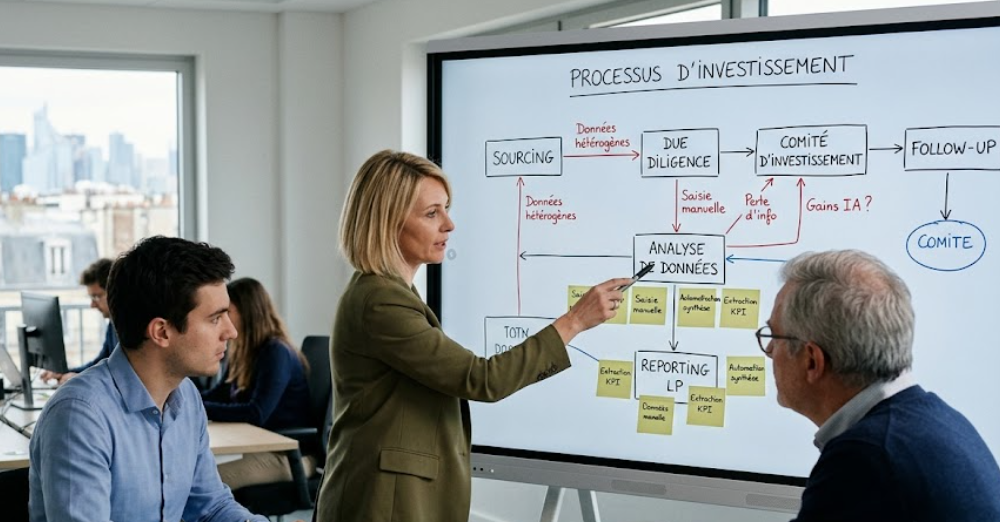
Par où commencer concrètement avec l'IA dans un fonds ?
La question du point de départ avec l’IA dans un fonds est souvent abordée sous le mauvais angle. Le sujet n’est pas de choisir un outil, mais d’identifier où l’IA peut améliorer concrètement l’efficacité opérationnelle, la qualité des données ou la qualité de décision.
Dans la majorité des sociétés de gestion, les premiers gains ne se situent pas sur des usages complexes ou “spectaculaires”. Ils apparaissent plutôt sur des tâches répétitives, consommatrices de temps et à faible valeur ajoutée intellectuelle : consolidation de reportings, préparation de synthèses, recherche d’informations dans des documents, production de comptes-rendus, structuration de données issues de fichiers hétérogènes ou traitement d’emails récurrents.
La première étape consiste donc à analyser les processus existants. Il faut comprendre comment les équipes travaillent réellement : où circulent les données, quels outils sont utilisés, où se trouvent les doubles saisies, les retraitements manuels, les pertes d’information ou les dépendances Excel.
Cette phase de cartographie est essentielle, car elle permet d’identifier les zones de friction opérationnelle et les points où l’IA peut apporter un gain immédiat sans modifier profondément les organisations.
La deuxième étape consiste à structurer un minimum la chaîne de donnée. Même une IA performante produit des résultats faibles si elle repose sur des données incohérentes, dispersées ou non gouvernées. Il n’est pas nécessaire de construire immédiatement une architecture complexe, mais il faut disposer d’une base fiable : données centralisées, définitions communes et règles de validation minimales.
Une fois ce socle posé, il devient possible de lancer quelques cas d’usage ciblés, avec trois caractéristiques : un périmètre limité, une valeur mesurable et un risque opérationnel faible.
Les projets les plus efficaces sont souvent très pragmatiques : automatisation de synthèses de mémos, extraction d’informations depuis une data room, préparation de reporting LP, assistance à la recherche documentaire ou structuration de KPI participations.
L’erreur classique consiste à vouloir déployer une stratégie IA globale avant d’avoir stabilisé les fondamentaux data et opérationnels. À l’inverse, les fonds qui avancent efficacement sont ceux qui construisent progressivement : structuration de la donnée, premiers cas d’usage métiers, montée en compétence des équipes, puis industrialisation.
L’IA doit être pensée comme une couche d’accélération au-dessus d’une organisation déjà maîtrisée. Sans fondations solides, elle amplifie les fragilités existantes. Avec une chaîne de donnée structurée et des usages bien cadrés, elle devient un levier opérationnel extrêmement puissant.
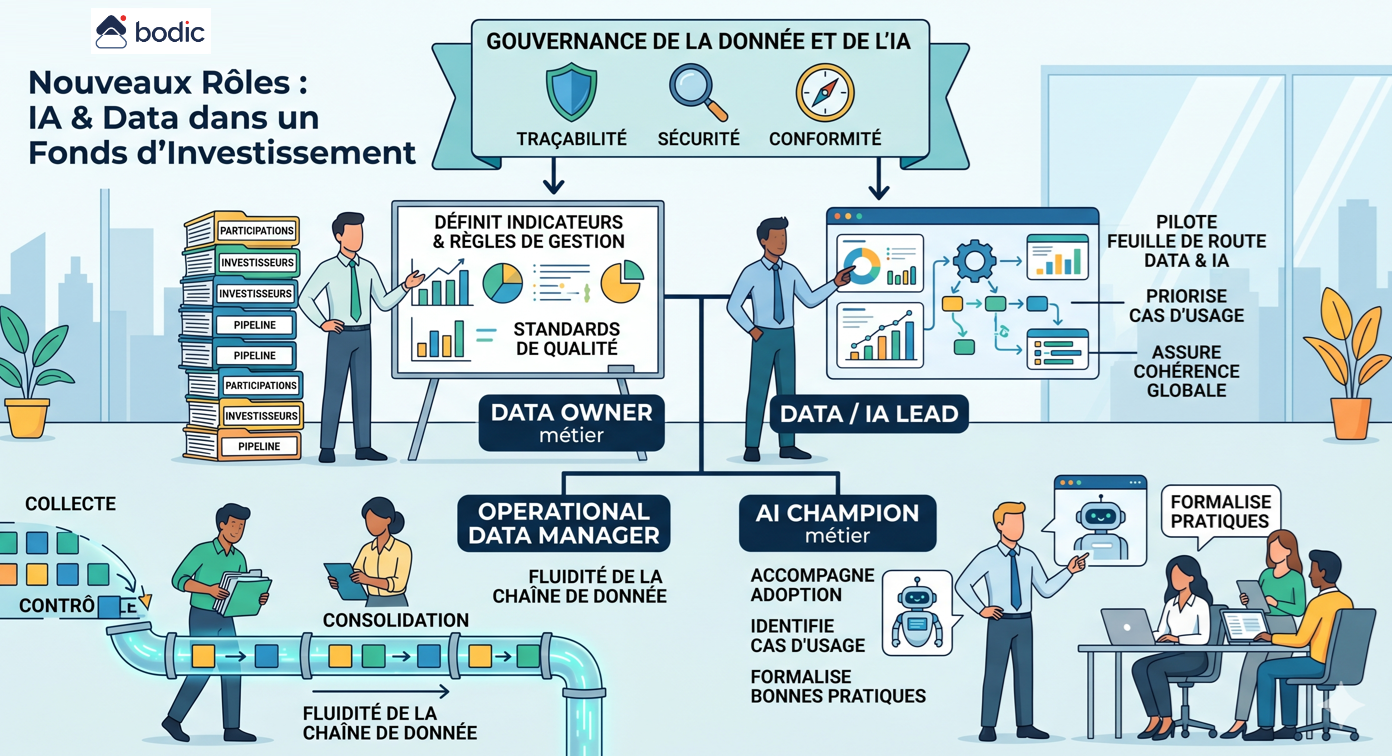
Quels sont les nouveaux rôles à faire émerger dans un fonds avec l'IA et la Data ?
L’introduction de l’IA et de la Data dans un fonds ne crée pas une rupture brutale des métiers, mais fait émerger de nouveaux rôles autour de la structuration de la donnée, de la gouvernance et de l’usage opérationnel.
Le premier rôle clé est celui de Data Owner métier. Il porte la responsabilité d’un périmètre de données critique, par exemple les participations, les investisseurs ou le pipeline. Il définit les indicateurs, les règles de gestion, les formats attendus et les standards de qualité. Sans ce rôle, la donnée reste diffuse et difficilement exploitable.
Le second rôle est celui de Data / IA Lead. Il pilote la feuille de route Data et IA du fonds, priorise les cas d’usage, arbitre les choix d’outils et assure la cohérence globale. Il agit comme un point de convergence entre les équipes d’investissement, le Middle Office, l’IR et les fonctions support.
Un troisième rôle émerge autour de l’Operational Data Manager. Il se situe au cœur des opérations, souvent au Middle Office, et s’assure que les flux de données sont correctement collectés, contrôlés, consolidés et diffusés. Il est responsable de la qualité opérationnelle et de la fluidité de la chaîne de donnée.
Avec l’IA, apparaît également un rôle plus spécifique d’AI Champion métier. Ce profil n’est pas nécessairement technique, mais il maîtrise les outils et leurs usages. Il accompagne les équipes dans l’adoption, identifie les cas d’usage pertinents et formalise les bonnes pratiques, notamment sur la supervision et les limites des agents IA.
Enfin, un rôle transverse de Gouvernance de la donnée et de l’IA devient indispensable. Il couvre les sujets de traçabilité, de sécurité, de conformité et de contrôle. Dans un contexte LP et réglementaire, la capacité à expliquer une donnée ou une décision devient aussi importante que la produire.
Il n’est pas nécessaire de structurer immédiatement une équipe dédiée. Dans la plupart des fonds, ces rôles émergent progressivement à partir des équipes existantes. L’enjeu est d’identifier les responsabilités, de clarifier les périmètres et de structurer une montée en compétence ciblée.
Le point clé reste l’ancrage métier. Ces rôles ne doivent pas être isolés dans une logique purement technique, mais intégrés au cœur des processus d’investissement et de gestion. C’est cette proximité qui permet de transformer la donnée en levier réel de performance.
Comment l'IA peut-elle améliorer concrètement la relation avec les investisseurs et les équipes IR ?
L’IA peut améliorer concrètement la relation avec les investisseurs et les équipes IR, à condition d’être utilisée comme un levier de fiabilisation et de cohérence, et non comme un outil de production automatisée de messages.
Les équipes IR font face à une exigence croissante : répondre plus vite, fournir une information précise, homogène et contextualisée, tout en s’adaptant à des profils d’investisseurs très différents. Dans ce contexte, l’IA peut jouer un rôle structurant.
Concrètement, elle permet de préparer des synthèses à partir de reportings internes, de reformuler des contenus selon le niveau d’expertise du destinataire, de retrouver rapidement une information dans l’historique des échanges ou dans une data room, et d’améliorer la cohérence globale des documents envoyés. Elle peut également assister la production de réponses standardisées (FAQ, emails types), tout en maintenant un niveau de qualité rédactionnelle élevé.
Mais l’apport réel de l’IA ne réside pas dans la vitesse d’exécution. Il réside dans la capacité à aligner les messages. Une communication IR de qualité repose sur une donnée unique, fiable et partagée entre les équipes. Si l’IA est branchée sur des sources fragmentées ou mal gouvernées, elle amplifie les incohérences au lieu de les corriger.
L’enjeu est donc d’ancrer l’IA dans une chaîne de donnée maîtrisée : mêmes chiffres entre la BI, les reportings et les communications investisseurs, traçabilité des sources, et contrôle éditorial systématique avant envoi. Dans ce cadre, l’IA devient un outil d’assistance puissant pour structurer, harmoniser et sécuriser la communication.
Le bon équilibre consiste à utiliser l’IA pour préparer et fiabiliser les contenus, tout en laissant aux équipes IR la responsabilité du ton, du contexte et de la relation. C’est cette combinaison qui permet d’améliorer à la fois l’efficacité opérationnelle et la confiance des investisseurs.
Comment former efficacement les équipes d'un fonds à l'IA sans tomber dans une acculturation trop théorique ?
Former efficacement les équipes d’un fonds à l’IA ne consiste pas à transmettre un savoir théorique, mais à transformer des pratiques concrètes de travail.
Une formation pertinente commence toujours par les situations réelles rencontrées par les équipes. Les professionnels de l’investissement n’ont pas besoin d’un discours général sur l’IA, mais d’une compréhension opérationnelle : ce que l’outil permet réellement, ses limites, et les conditions dans lesquelles il peut être utilisé sans dégrader la rigueur des processus.
Cela implique de segmenter les approches. Les besoins d’un partner, d’un analyste, d’une équipe IR, compliance, middle office ou ESG sont profondément différents. Une formation efficace repose donc sur un socle commun (principes, risques, bonnes pratiques), complété par des cas d’usage ciblés : analyse d’un mémo d’investissement, synthèse d’un Information Memorandum, exploration d’une data room, préparation d’un comité, screening sectoriel ou gestion d’un échange complexe avec un LP.
La clé réside dans l’applicabilité immédiate. Chaque module doit permettre un passage à l’action dès le lendemain, avec des gains visibles et mesurables. C’est ce qui transforme une acculturation en adoption réelle.
Mais la formation ne peut pas être pensée comme un événement ponctuel. Les modèles évoluent, les outils changent, les usages se précisent et les risques se déplacent. Une démarche efficace s’inscrit dans la durée : sensibilisation initiale, ateliers pratiques par métier, retours d’expérience entre pairs, et accompagnement continu pour ajuster les pratiques.
Enfin, un point souvent sous-estimé : former à l’IA, c’est aussi former au discernement. Savoir quand utiliser l’outil, quand s’en méfier, et comment contrôler ses résultats est aussi important que savoir l’utiliser.
Le bon dispositif combine donc pédagogie, pratique et itération. C’est cette logique qui permet d’ancrer durablement l’IA dans les processus d’un fonds, sans tomber dans une approche théorique déconnectée du terrain.
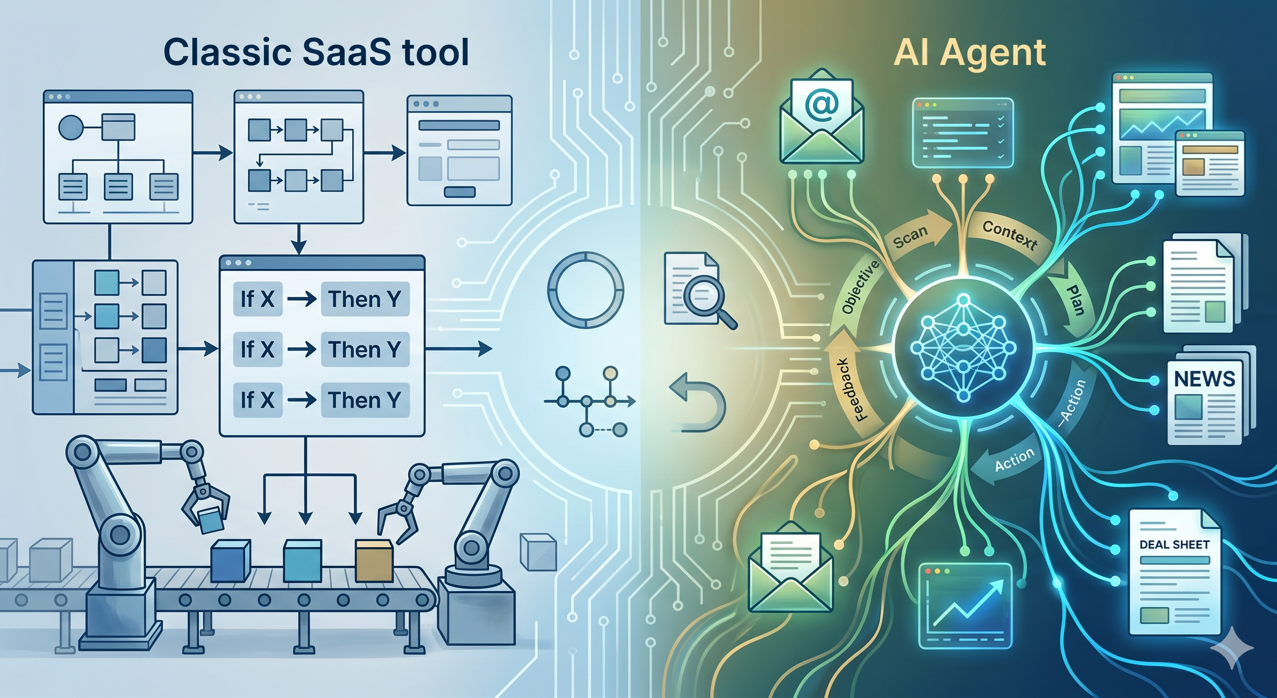
Qu'est-ce qu'un agent IA dans le contexte d'un fonds, et en quoi est-ce différent d'un outil SaaS classique ?
Un SaaS classique exécute des actions préprogrammées : si X, alors Y. Un agent IA, lui, reçoit un objectif, comprend le contexte, planifie ses étapes et exécute une séquence d'actions en s'adaptant aux données qu'il rencontre. Cette autonomie est son intérêt et son risque.
Dans un fonds, les cas d'usage pertinents pour un agent sont bien cadrés : traitement d'emails fournisseurs, enrichissement d'une fiche deal, préparation automatique d'un pack de comité à partir d'une data room, surveillance de signaux sur des entreprises cibles. Les cas mal cadrés (prise de décision d'investissement, envoi d'une communication à un LP sans relecture) ne sont pas des cas pour agents, ce sont des cas pour humains assistés.
Le bon agent a quatre caractéristiques : un périmètre clair, une supervision humaine à chaque étape sensible, une traçabilité complète, et une réversibilité en cas de comportement inattendu. Bodic développe ses agents selon ces principes dans le cadre de ses développements sur mesure.
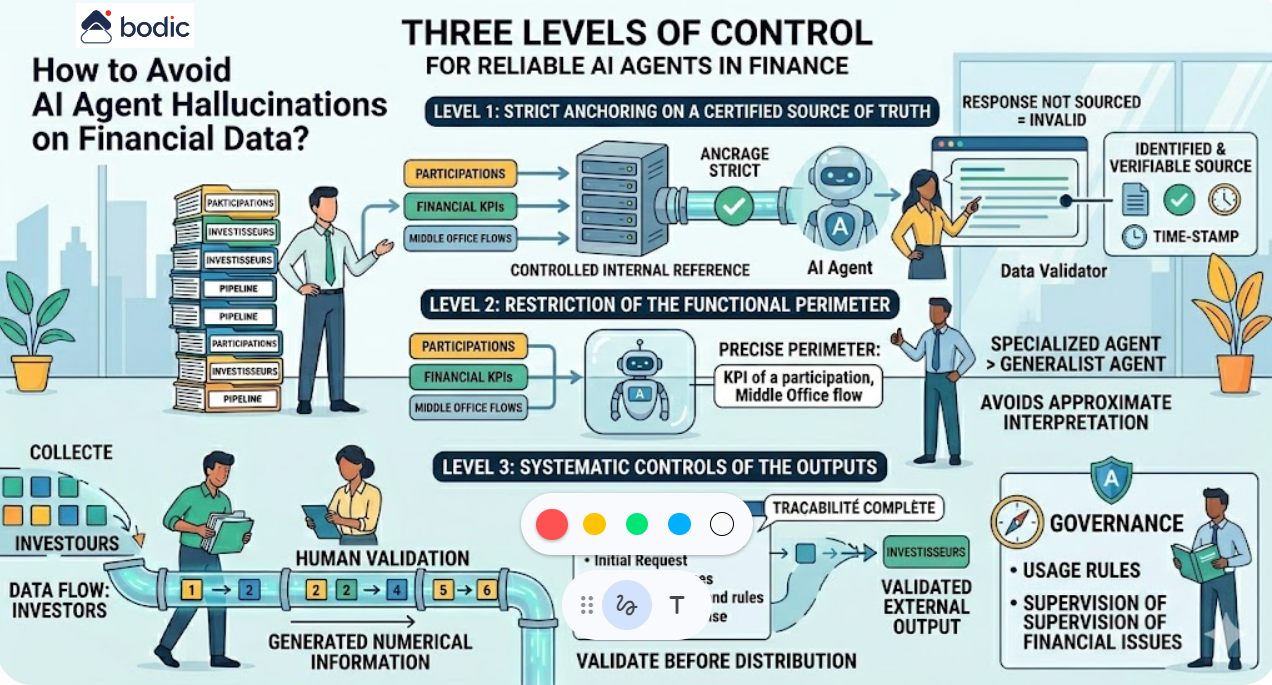
Comment éviter les hallucinations d'un agent IA sur des données financières ?
Les hallucinations constituent le principal risque d’usage des agents IA dans un contexte financier. Elles ne relèvent pas d’erreurs aléatoires, mais d’un comportement structurel des modèles lorsqu’ils ne disposent pas d’une information fiable ou suffisamment contrainte.
Trois niveaux de contrôle permettent de réduire fortement ce risque.
Le premier est l’ancrage strict sur une source de vérité certifiée. L’agent ne doit pas s’appuyer sur des connaissances générales ou des données implicites, mais uniquement sur un référentiel interne maîtrisé. Chaque réponse doit être associée à une source identifiable, accessible et vérifiable. Une réponse non sourcée doit être considérée comme invalide par défaut.
Le deuxième niveau est la restriction du périmètre fonctionnel et informationnel. Un agent doit intervenir sur un domaine précis, avec un jeu de données limité et maîtrisé. Plus le périmètre est large, plus le risque d’interprétation approximative augmente. En pratique, un agent spécialisé sur un sous-ensemble de données financières, par exemple les KPI d’une participation ou les flux Middle Office, est significativement plus fiable qu’un agent généraliste.
Le troisième niveau est la mise en place de contrôles systématiques sur les outputs. Toute information chiffrée destinée à un usage externe, notamment à destination des investisseurs, doit faire l’objet d’une validation humaine. Cette validation doit s’appuyer sur une traçabilité complète : requête initiale, sources mobilisées, transformations appliquées et réponse générée.
Au-delà de ces principes, l’architecture technique joue un rôle déterminant. Une approche structurée consiste à isoler la couche IA des données brutes, à passer par un référentiel centralisé, puis à exposer uniquement des données validées aux agents. Cela permet de contrôler précisément ce que l’agent peut voir et utiliser.
Enfin, il est important de traiter les hallucinations comme un sujet de gouvernance, et non uniquement comme un problème technique. Cela implique de définir des règles d’usage, des niveaux de responsabilité et des mécanismes de supervision adaptés aux enjeux financiers.
Un agent fiable n’est pas celui qui “répond bien”, mais celui dont chaque réponse peut être expliquée, tracée et vérifiée.
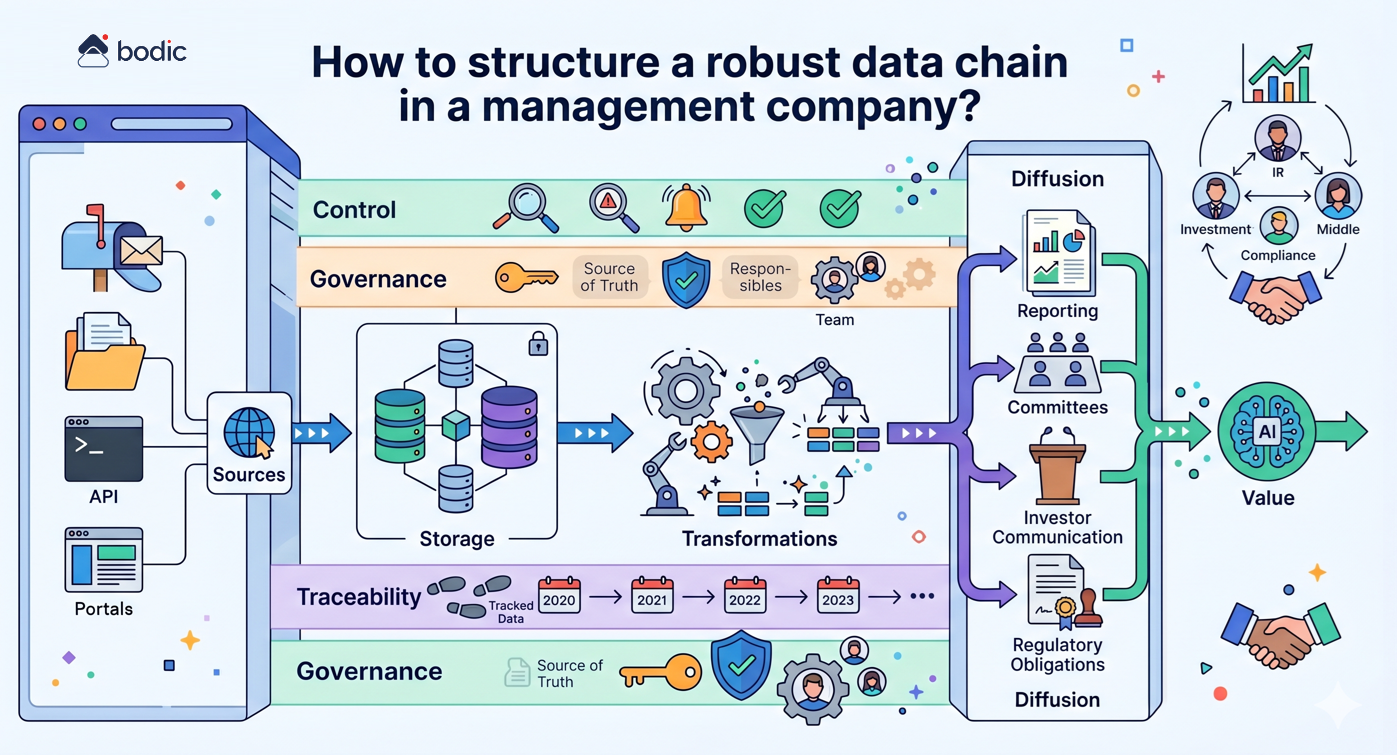
Comment structurer une chaîne de données robuste dans une société de gestion ?
Structurer une chaîne de données robuste dans une société de gestion consiste à rendre explicite, maîtrisée et fiable la circulation de l’information, depuis sa production jusqu’à son utilisation finale.
Concrètement, cela implique de formaliser plusieurs étapes clés : identifier les sources de données (emails, fichiers, portails, API), définir les espaces de stockage (bases internes, data warehouse, outils métiers), organiser les transformations (nettoyage, enrichissement, consolidation), puis structurer la diffusion vers les usages finaux (reporting, comités, communication investisseurs, obligations réglementaires).
Une chaîne de données robuste repose sur quelques principes fondamentaux.
D’abord, chaque donnée critique doit être définie clairement : une source identifiée, un format de référence, une fréquence de mise à jour et un responsable. Sans cette discipline, les écarts apparaissent rapidement entre équipes, outils et livrables.
Ensuite, il est essentiel de limiter les redondances. La multiplication de fichiers Excel, d’extractions locales ou de versions parallèles crée des incohérences et fragilise la confiance dans les chiffres. L’objectif est de converger vers une “source de vérité” partagée, accessible et contrôlée.
La traçabilité est également centrale. Chaque chiffre utilisé dans un reporting ou un comité doit pouvoir être relié à son origine, avec un historique des transformations. Cela devient critique dès lors que les exigences LP ou réglementaires augmentent.
Enfin, une chaîne robuste intègre des mécanismes de contrôle : règles de validation, alertes en cas d’anomalie, supervision humaine sur les points sensibles. Ce cadre permet d’assurer la qualité sans ralentir les opérations.
L’enjeu dépasse largement la technique. Une chaîne de données bien structurée améliore la qualité des reportings, fluidifie la collaboration entre équipes (investissement, IR, middle office, compliance), renforce la crédibilité vis-à-vis des investisseurs et accélère la prise de décision.
C’est aussi une condition indispensable pour déployer efficacement des outils d’IA. Sans données structurées, fiables et gouvernées, l’IA amplifie les défauts existants au lieu de créer de la valeur.
Peut-on automatiser efficacement le reporting des participations ?
Oui, l’automatisation du reporting des participations est non seulement possible, mais constitue l’un des leviers les plus immédiats d’amélioration opérationnelle dans un fonds.
Dans la majorité des organisations, le processus repose encore sur des collectes manuelles, des fichiers hétérogènes transmis par les participations, et des consolidations réalisées sous Excel. Ce modèle introduit plusieurs fragilités : dépendance à des formats non standardisés, risques d’erreurs lors des retraitements, manque de traçabilité et délais de production élevés.
Une automatisation efficace repose sur la structuration de la chaîne de donnée en amont.
Première étape, standardiser les inputs. Cela implique de définir un dictionnaire de données commun avec les participations, incluant des indicateurs clairement définis, des formats attendus, des règles de calcul explicites et un calendrier de remontée. Sans cette normalisation, toute automatisation reste partielle.
Deuxième étape, organiser la collecte. Elle peut passer par des portails dédiés, des templates structurés ou des connecteurs. L’objectif est de réduire les variations de format et de limiter les interventions manuelles.
Troisième étape, industrialiser les contrôles. Des règles automatiques permettent de détecter les incohérences, les écarts de variation, les ruptures de séries ou les anomalies entre indicateurs liés. Ces contrôles doivent être systématiques et traçables.
Quatrième étape, centraliser dans une source de vérité unique. Les données consolidées doivent alimenter directement les outils de reporting, de BI et de communication investisseurs, afin d’éviter toute duplication ou retraitement local.
Dans ce cadre, l’automatisation permet de sécuriser la production, de réduire les délais et d’augmenter significativement la fiabilité des livrables.
Le rôle des équipes évolue. Elles passent d’une logique de production à une logique de contrôle et d’analyse. L’enjeu n’est plus de consolider, mais d’interpréter les données, d’identifier les signaux faibles et de préparer les décisions.
Enfin, le point critique reste la gouvernance. Une automatisation sans règles claires sur la qualité des données, les responsabilités et les processus de validation peut dégrader la fiabilité globale. L’automatisation doit s’inscrire dans un cadre rigoureux, orienté contrôle, traçabilité et cohérence.
Comment utiliser l'IA pour préparer un comité d'investissement sans dégrader la qualité du jugement ?
L’IA peut améliorer significativement la préparation d’un comité d’investissement, à condition de ne pas dégrader ce qui fait la qualité d’une décision : la clarté du raisonnement, la hiérarchisation des informations et la solidité de la conviction.
Le principal risque est bien identifié : l’IA augmente la quantité d’informations disponibles : plus de données, plus de scénarios, plus de signaux, sans garantir une meilleure décision. Cette abondance peut même créer une surcharge cognitive et diluer les points réellement structurants. Il est donc essentiel de ne pas confondre richesse informationnelle et qualité de jugement.
Le bon usage consiste à organiser l’IA autour du processus de décision, et non l’inverse. Cela implique d’identifier en amont les questions clés qui seront débattues en comité, puis de produire des synthèses ciblées, calibrées pour éclairer ces questions sans chercher l’exhaustivité. L’objectif est de réduire le bruit pour renforcer le signal.
L’IA est particulièrement utile pour préparer ces supports : structurer un mémo d’investissement, synthétiser une data room, rapprocher différentes sources d’information, ou reformuler des analyses pour en améliorer la lisibilité. Mais elle ne doit pas conclure à la place des équipes. La responsabilité de l’analyse et de la recommandation reste humaine.
Un point clé est la traçabilité. Chaque chiffre ou affirmation utilisé en comité doit pouvoir être relié à une source identifiable. L’IA peut aider à structurer cette traçabilité, mais elle doit s’appuyer sur une chaîne de données fiable et gouvernée.
En séance, son rôle est plus tactique : retrouver rapidement une information précise, vérifier un point, explorer un scénario alternatif à la demande. Utilisée ainsi, elle devient un outil d’appui, sans interférer avec la dynamique de décision.
Enfin, le bon indicateur de performance n’est pas le temps de préparation économisé, mais la qualité des décisions prises. Une IA bien utilisée doit améliorer la compréhension des enjeux, la robustesse des échanges et la capacité à trancher pas simplement accélérer la production de documents.
Nous utilisons des cookies pour vous offrir la meilleure expérience sur notre site. Vous pouvez en savoir plus sur les cookies que nous utilisons ou les désactiver dans les paramètres.