Qu'est-ce qu'un agent IA dans le contexte d'un fonds, et en quoi est-ce différent d'un outil SaaS classique ?
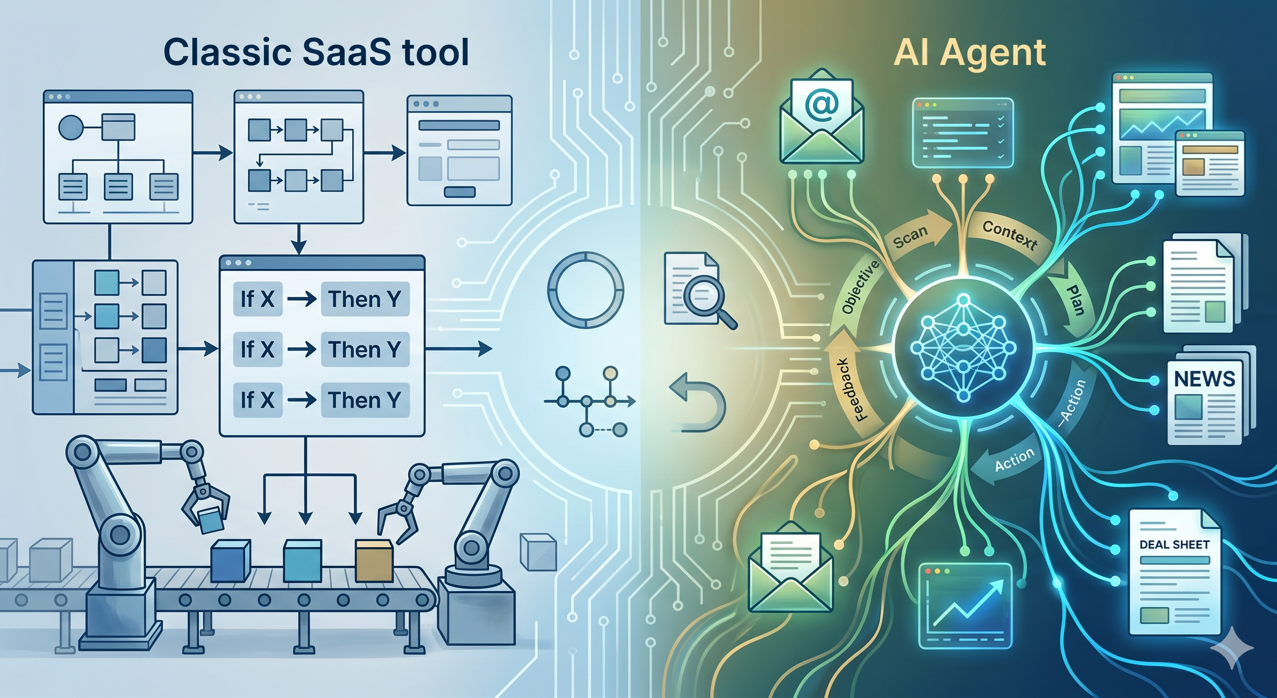
Un SaaS classique exécute des actions préprogrammées : si X, alors Y. Un agent IA, lui, reçoit un objectif, comprend le contexte, planifie ses étapes et exécute une séquence d'actions en s'adaptant aux données qu'il rencontre. Cette autonomie est son intérêt et son risque.
Dans un fonds, les cas d'usage pertinents pour un agent sont bien cadrés : traitement d'emails fournisseurs, enrichissement d'une fiche deal, préparation automatique d'un pack de comité à partir d'une data room, surveillance de signaux sur des entreprises cibles. Les cas mal cadrés (prise de décision d'investissement, envoi d'une communication à un LP sans relecture) ne sont pas des cas pour agents, ce sont des cas pour humains assistés.
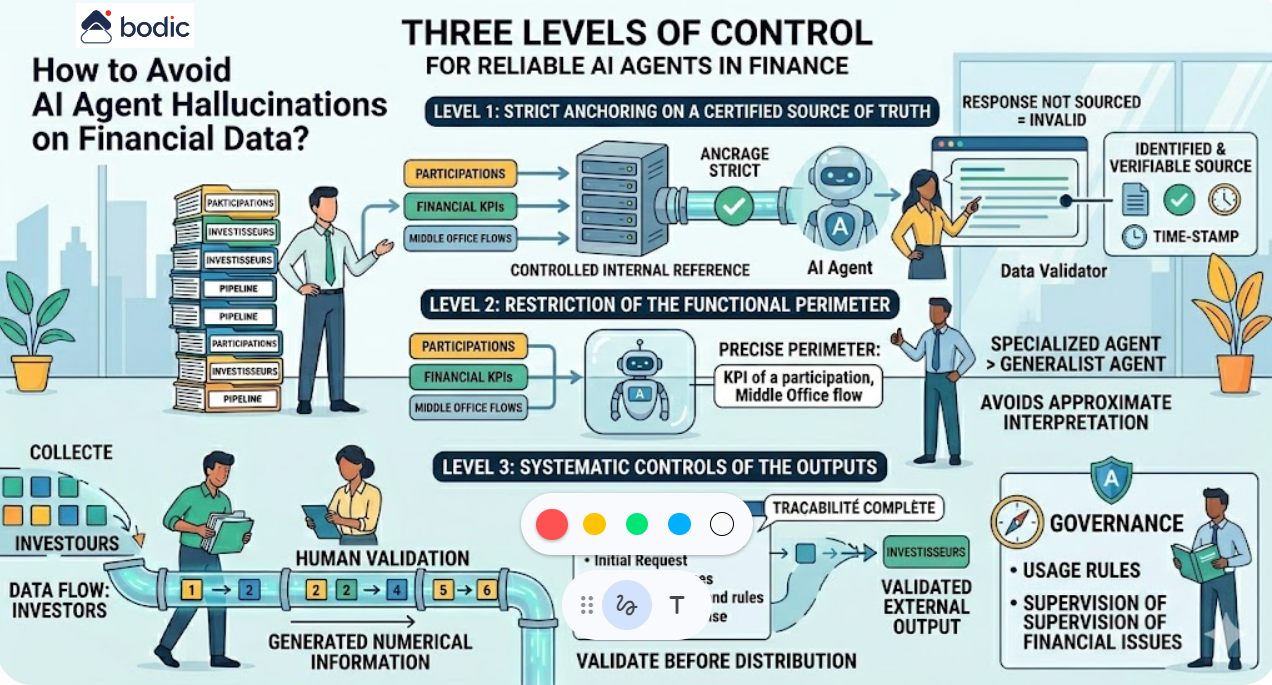
Le bon agent a quatre caractéristiques : un périmètre clair, une supervision humaine à chaque étape sensible, une traçabilité complète, et une réversibilité en cas de comportement inattendu. Bodic développe ses agents selon ces principes dans le cadre de ses développements sur mesure.
Dans un fonds, les cas d'usage pertinents pour un agent sont bien cadrés : traitement d'emails fournisseurs, enrichissement d'une fiche deal, préparation automatique d'un pack de comité à partir d'une data room, surveillance de signaux sur des entreprises cibles. Les cas mal cadrés (prise de décision d'investissement, envoi d'une communication à un LP sans relecture) ne sont pas des cas pour agents, ce sont des cas pour humains assistés.
Le bon agent a quatre caractéristiques : un périmètre clair, une supervision humaine à chaque étape sensible, une traçabilité complète, et une réversibilité en cas de comportement inattendu. Bodic développe ses agents selon ces principes dans le cadre de ses développements sur mesure.