The question of where to start with AI in a fund is often approached from the wrong angle. The point is not to choose a tool, but to identify where AI can concretely improve operational efficiency, data quality or decision quality.
In the majority of asset management companies, the first gains are not to be found in complex or "spectacular" applications. Instead, they appear on repetitive, time-consuming tasks with little intellectual added value: consolidating reports, preparing summaries, searching for information in documents, producing reports, structuring data from heterogeneous files or processing recurring e-mails.
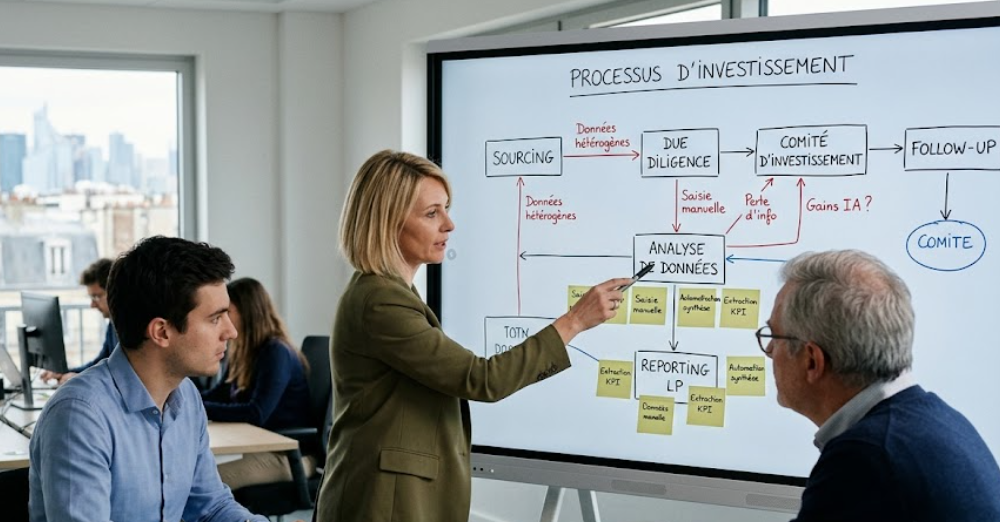
The first step is to analyze existing processes. We need to understand how teams actually work: where data flows, what tools are used, where there is double entry, manual reprocessing, loss of information or Excel dependencies.
This mapping phase is essential, as it identifies areas of operational friction and points where AI can bring immediate gain without profoundly changing organizations.
The second step is to structure the data chain to a minimum. Even high-performance AI produces weak results if it relies on inconsistent, dispersed or ungoverned data. You don't need to build a complex architecture right away, but you do need a reliable foundation: centralized data, common definitions and minimal validation rules.
Once this foundation has been laid, it's possible to launch a few targeted use cases, with three characteristics: limited scope, measurable value and low operational risk.
The most effective projects are often highly pragmatic: automating memo summaries, extracting information from a data room, preparing LP reports, assisting document research or structuring participative KPIs.
The classic mistake is to try to deploy a global AI strategy before having stabilized the data and operational fundamentals. Conversely, funds that move forward effectively are those that build progressively: structuring data, first business use cases, ramping up team skills, then industrialization.
AI should be thought of as a layer of acceleration on top of an already mastered organization. Without solid foundations, it amplifies existing weaknesses. With a structured data chain and well-defined uses, it becomes an extremely powerful operational lever.
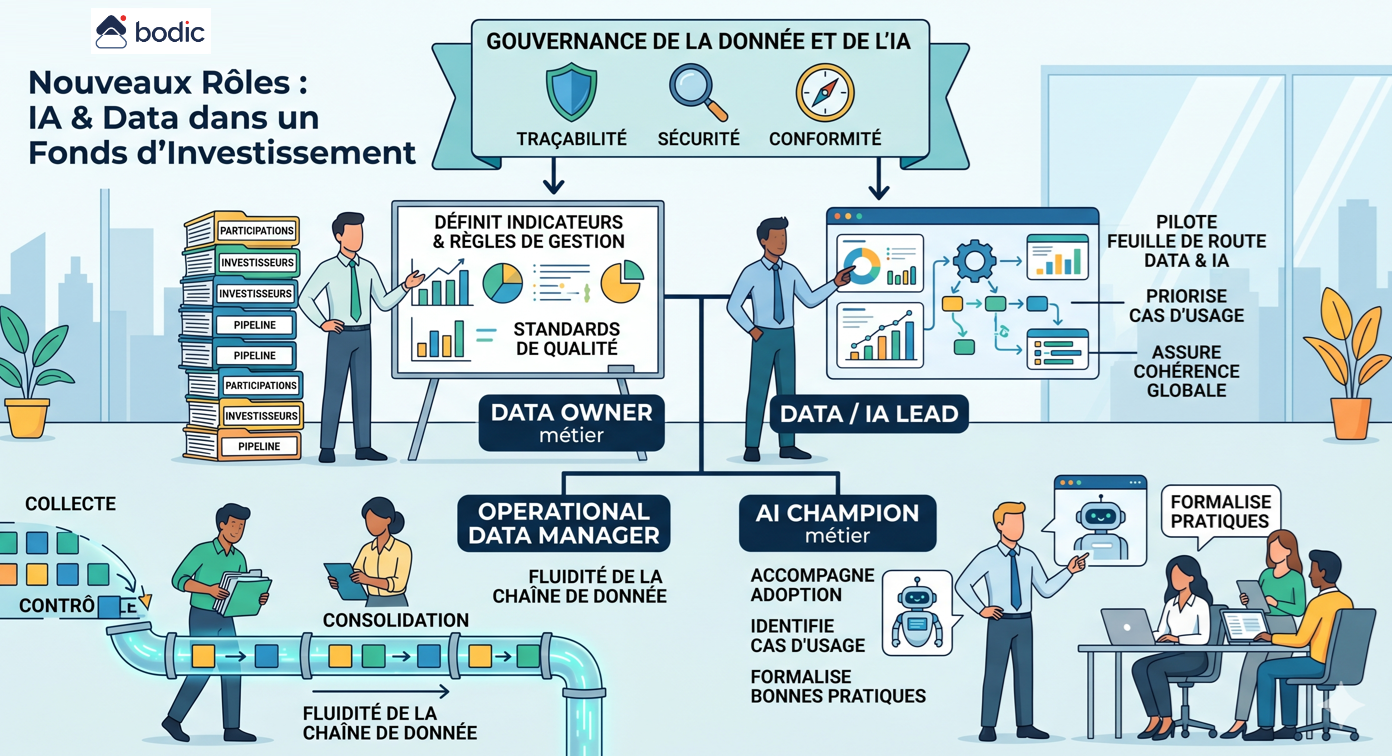
What new roles are emerging in a fund with AI and Data?
The introduction of AI and Data into a fund doesn't create an abrupt disruption of business lines, but does give rise to new roles around data structuring, governance and operational use.
The first key role is that of business Data Owner. He or she is responsible for a critical perimeter of data, such as shareholdings, investors or the pipeline. He or she defines indicators, management rules, expected formats and quality standards. Without this role, data remains diffuse and difficult to exploit.
The second role is that of Data / AI Lead. He/she steers the fund's Data and AI roadmap, prioritizes use cases, arbitrates tool choices and ensures overall consistency. He acts as a point of convergence between the investment teams, Middle Office, IR and support functions.
A third role is emerging around the Operational Data Manager. Located at the heart of operations, often in the Middle Office, he or she ensures that data flows are correctly collected, controlled, consolidated and disseminated. He or she is responsible for the operational quality and fluidity of the data chain.
With AI, a more specific role of Business AI Champion is also emerging. This profile is not necessarily technical, but has a thorough command of the tools and their uses. He or she supports teams in their adoption, identifies relevant use cases and formalizes best practices, particularly with regard to the supervision and limits of AI agents.
Finally, a cross-functional role for Data and AI Governance is becoming essential. This covers traceability, security, compliance and control. In an LP and regulatory context, the ability to explain a piece of data or a decision becomes as important as producing it.
It's not necessary to set up a dedicated team right away. In most funds, these roles emerge gradually from existing teams. The challenge is to identify responsibilities, clarify scopes of work and structure targeted skills development.
The key point is to ensure that they are rooted in the business. These roles must not be isolated in a purely technical logic, but integrated into the heart of the investment and management processes. It is this proximity that enables data to be transformed into a real performance lever.
How can AI concretely improve relations with investors and IR teams?
AI can concretely improve relations with investors and IR teams, provided it is used as a lever for reliability and consistency, and not as a tool for automated message production.
IR teams face a growing requirement to respond faster, provide accurate, consistent and contextualized information, while adapting to very different investor profiles. In this context, AI can play a structuring role.
In concrete terms, it can be used to prepare summaries from internal reports, to reformulate content according to the recipient's level of expertise, to quickly find information in the history of exchanges or in a data room, and to improve the overall consistency of documents sent. It can also assist in the production of standardized responses (FAQs, standard emails), while maintaining a high level of editorial quality.
But the real contribution of AI does not lie in speed of execution. It lies in the ability to align messages. High-quality IR communication relies on single, reliable data shared between teams. If AI is plugged into fragmented or poorly governed sources, it amplifies inconsistencies instead of correcting them.
The challenge is therefore to anchor AI in a controlled data chain: same figures between BI, reporting and investor communications, traceability of sources, and systematic editorial control before sending. In this context, AI becomes a powerful support tool for structuring, harmonizing and securing communication.
The right balance consists in using AI to prepare and make content reliable, while leaving IR teams responsible for tone, context and relationship. It is this combination that improves both operational efficiency and investor confidence.
How do you effectively train fund teams in AI without becoming too theoretical?
Effectively training fund teams in AI is not about imparting theoretical knowledge, but about transforming concrete work practices.
Relevant training always starts with the real situations encountered by teams. Investment professionals don't need a general discourse on AI, but an operational understanding: what the tool actually enables, its limitations, and the conditions under which it can be used without degrading the rigor of processes.
This means segmenting approaches. The needs of a partner, an analyst, an IR, compliance, middle office or ESG team are profoundly different. Effective training is therefore based on a common foundation (principles, risks, best practices), supplemented by targeted use cases: analyzing an investment memo, summarizing an Information Memorandum, exploring a data room, preparing for a committee, sector screening or managing a complex exchange with an LP.
The key is immediate applicability. Each module must enable action to be taken the very next day, with visible and measurable gains. This is what transforms acculturation into real adoption.
But training cannot be seen as a one-off event. Models evolve, tools change, uses become clearer and risks shift. An effective approach requires a long-term approach: initial awareness-raising, practical workshops by business line, feedback from peers, and ongoing support to adjust practices.
Finally, a point that is often underestimated: training in AI also means training in discernment. Knowing when to use the tool, when to be wary of it, and how to control its results is just as important as knowing how to use it.
The right system therefore combines teaching, practice and iteration. It is this logic that enables AI to be firmly anchored in a fund's processes, without falling into a theoretical approach disconnected from the field.
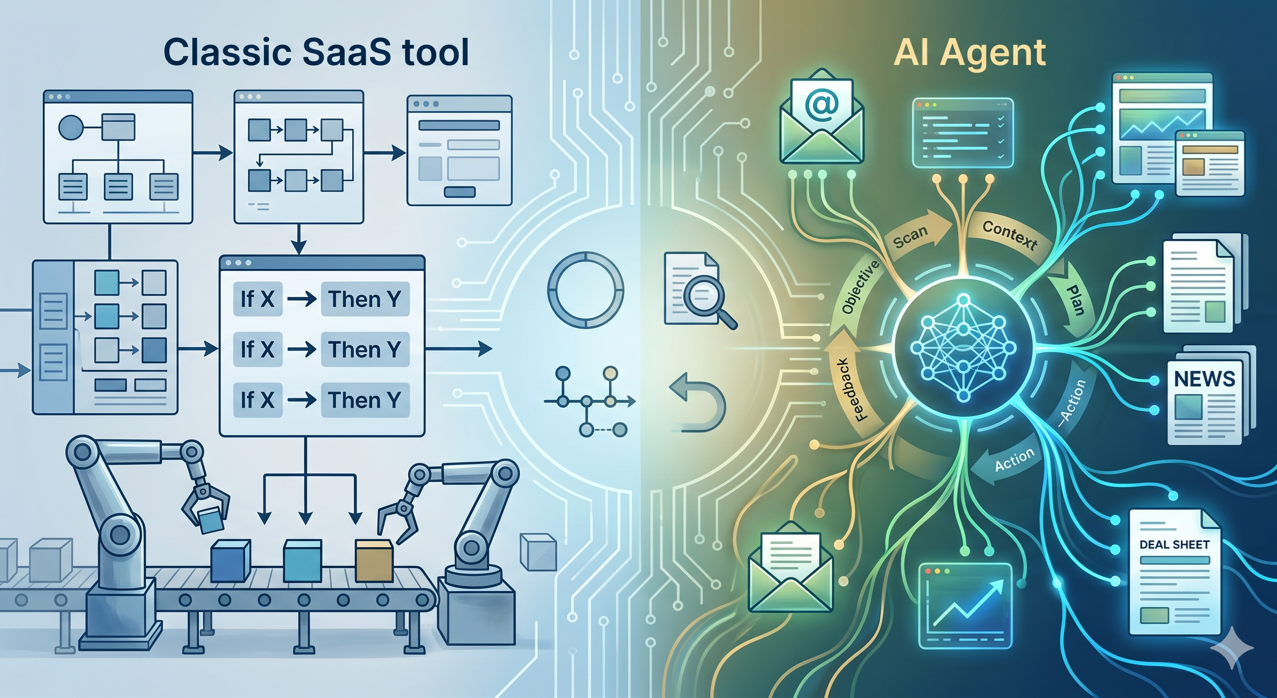
What is an AI agent in the context of a fund, and how is it different from a classic SaaS tool?
A classic SaaS executes pre-programmed actions: if X, then Y. An AI agent, on the other hand, receives an objective, understands the context, plans its steps and executes a sequence of actions, adapting to the data it encounters. This autonomy is both its interest and its risk.
In a fund, the relevant use cases for an agent are well-defined: processing supplier emails, enriching a deal sheet, automatically preparing a committee pack from a data room, monitoring signals on target companies. Ill-framed cases (making an investment decision, sending a communication to an LP without proofreading) are not cases for agents, they are cases for assisted humans.
A good agent has four characteristics: a clear perimeter, human supervision at every sensitive stage, complete traceability, and reversibility in the event of unexpected behavior. Bodic develops its agents according to these principles as part of its customized developments.
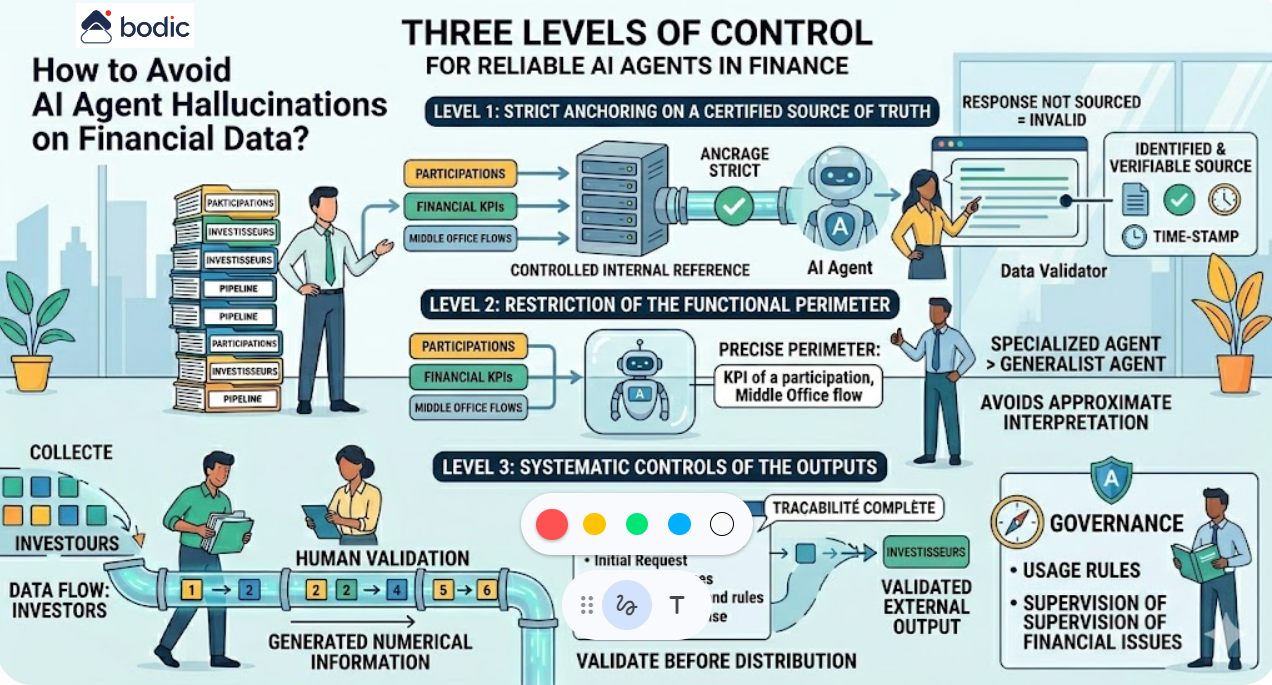
How to prevent an AI agent from hallucinating financial data?
Hallucinations are the main risk when using AI agents in a financial context. They are not the result of random errors, but of the structural behavior of models in the absence of reliable or sufficiently constrained information.
Three levels of control can greatly reduce this risk.
The first is strict anchoring on a certified source of truth. The agent must not rely on general knowledge or implicit data, but only on a controlled internal repository. Each answer must be associated with an identifiable, accessible and verifiable source. An unsourced answer must be considered invalid by default.
The second level is the restriction of the functional and informational perimeter. An agent must intervene in a precise domain, with a limited and controlled set of data. The wider the scope, the greater the risk of approximate interpretation. In practice, an agent who specializes in a subset of financial data, such as a shareholding's KPIs or Middle Office flows, is significantly more reliable than a generalist agent.
The third level is the implementation of systematic controls on outputs. All numerical information intended for external use, in particular for investors, must be validated by a human being. This validation must be based on complete traceability: initial request, sources used, transformations applied and response generated.
Beyond these principles, technical architecture plays a decisive role. A structured approach consists in isolating the AI layer from raw data, using a centralized repository, then exposing only validated data to agents. This allows precise control over what the agent can see and use.
Finally, it's important to treat hallucinations as a governance issue, not just a technical problem. This means defining rules of use, levels of responsibility and supervisory mechanisms adapted to the financial stakes involved.
A reliable agent is not one that "responds well", but one whose every response can be explained, traced and verified.
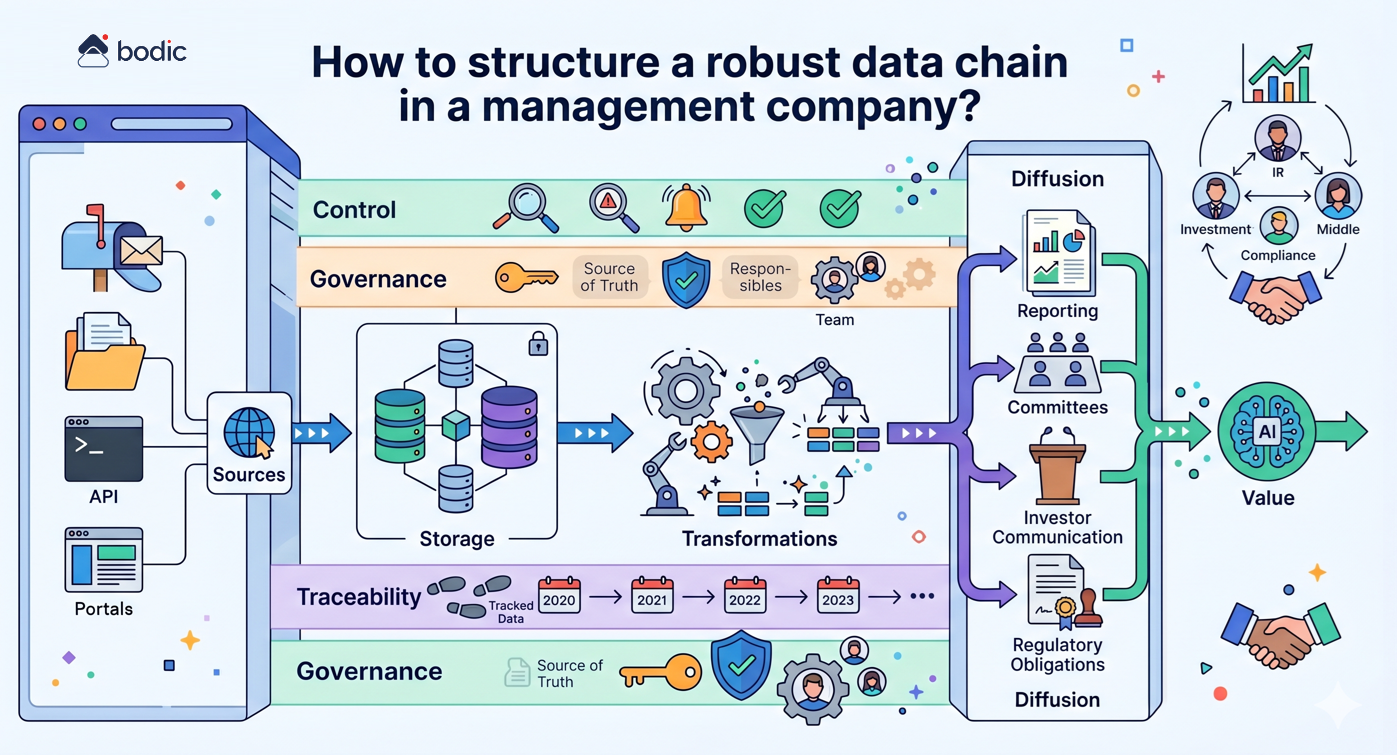
How do you structure a robust data chain in an asset management company?
Structuring a robust data chain in a management company involves making the circulation of information explicit, controlled and reliable, from its production to its final use.
In concrete terms, this involves formalizing several key stages: identifying data sources (emails, files, portals, APIs), defining storage spaces (internal databases, data warehouse, business tools), organizing transformations (cleansing, enrichment, consolidation), then structuring distribution to end-users (reporting, committees, investor communication, regulatory obligations).
A robust data chain is based on a few fundamental principles.
First and foremost, each piece of critical data must be clearly defined: an identified source, a reference format, an update frequency and a person in charge. Without this discipline, gaps quickly appear between teams, tools and deliverables.
Next, it's essential to limit redundancy. The multiplication of Excel files, local extractions or parallel versions creates inconsistencies and undermines confidence in the figures. The aim is to converge towards a shared, accessible and controlled "source of truth".
Traceability is also central. Every figure used in a report or committee must be traceable back to its origin, with a history of transformations. This becomes critical as LP and regulatory requirements increase.
Finally, a robust chain includes control mechanisms: validation rules, alerts in the event of anomalies, and human supervision of sensitive points. This framework ensures quality without slowing down operations.
The challenge goes far beyond the technical. A well-structured data chain improves the quality of reporting, facilitates collaboration between teams (investment, IR, middle office, compliance), strengthens credibility with investors and accelerates decision-making.
It's also a prerequisite for the effective deployment of AI tools. Without structured, reliable and governed data, AI amplifies existing shortcomings instead of creating value.
Can investment reporting be automated efficiently?
Yes, automating investment reporting is not only possible, it's also one of the most immediate ways of improving a fund's operations.
In the majority of organizations, the process is still based on manual data collection, with heterogeneous files transmitted by the investments, and consolidations carried out in Excel. This model introduces a number of weaknesses: dependence on non-standardized formats, risk of errors during reprocessing, lack of traceability and long production lead times.
Effective automation depends on structuring the data chain upstream.
The first step is to standardize inputs. This involves defining a common data dictionary with all participants, including clearly defined indicators, expected formats, explicit calculation rules and a reporting schedule. Without this standardization, all automation remains partial.
The second step is to organize data collection. This can involve dedicated portals, structured templates or connectors. The aim is to reduce format variations and limit manual intervention.
Third step: industrialize controls. Automatic rules are used to detect inconsistencies, variations, breaks in series or anomalies between related indicators. These controls must be systematic and traceable.
Fourth step: centralize in a single source of truth. Consolidated data must be fed directly into reporting, BI and investor communication tools, to avoid any duplication or local reprocessing.
In this context, automation helps to secure production, reduce lead times and significantly increase the reliability of deliverables.
The role of teams is changing. They move from a production logic to a control and analysis logic. The challenge is no longer to consolidate, but to interpret data, identify weak signals and prepare decisions.
Finally, governance remains the critical point. Automation without clear rules on data quality, responsibilities and validation processes can degrade overall reliability. Automation must be part of a rigorous framework, focused on control, traceability and consistency.
How can AI be used to prepare an investment committee without degrading the quality of the judgement?
AI can significantly improve the preparation of an investment committee, provided that it does not degrade what makes a quality decision: clarity of reasoning, prioritization of information and solidity of conviction.
The main risk is well identified: AI increases the amount of information available: more data, more scenarios, more signals, without guaranteeing a better decision. This abundance can even create cognitive overload and dilute the truly structuring points. It is therefore essential not to confuse information wealth with quality of judgment.
The right approach is to organize AI around the decision-making process, and not the other way around. This means identifying upstream the key questions that will be debated in committee, then producing targeted summaries, calibrated to shed light on these questions without seeking exhaustiveness. The aim is to reduce the noise to enhance the signal.
AI is particularly useful for preparing these supports: structuring an investment memo, synthesizing a data room, reconciling different sources of information, or reformulating analyses to improve readability. But it should not take the place of the teams. The responsibility for analysis and recommendation remains with the individual.
A key point is traceability. Every figure or assertion used in committee must be traceable to an identifiable source. AI can help structure this traceability, but it must be based on a reliable, governed data chain.
In meetings, its role is more tactical: quickly retrieving specific information, verifying a point, exploring an alternative scenario on request. Used in this way, it becomes a support tool, without interfering with the decision-making process.
Finally, the right performance indicator is not the preparation time saved, but the quality of the decisions made. Well-used AI must improve understanding of the issues at stake, the robustness of exchanges and the ability to reach decisions, not simply speed up document production.