Wo soll man mit KI in einem Fonds konkret anfangen?
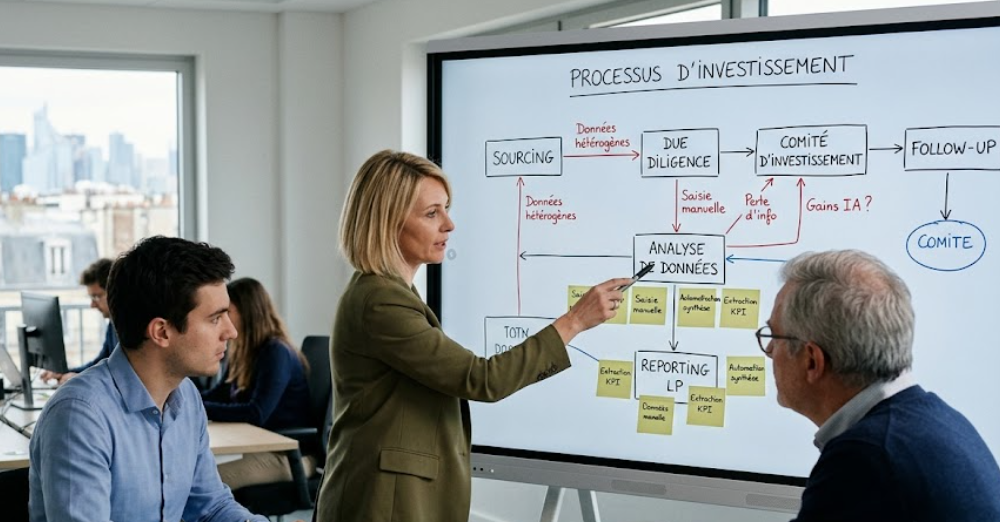
Die Frage, wo man mit KI in einem Fonds anfangen soll, wird oft aus dem falschen Blickwinkel angegangen. Es geht nicht darum, ein Werkzeug auszuwählen, sondern zu ermitteln, wo KI die betriebliche Effizienz, die Datenqualität oder die Entscheidungsqualität konkret verbessern kann.
In der Mehrzahl der Verwaltungsgesellschaften sind die ersten Gewinne nicht bei komplexen oder "spektakulären" Anwendungen zu verzeichnen. Sie treten vielmehr bei sich wiederholenden, zeitraubenden Aufgaben mit geringem intellektuellen Mehrwert auf: Konsolidierung von Berichten, Erstellung von Zusammenfassungen, Suche nach Informationen in Dokumenten, Erstellung von Berichten, Strukturierung von Daten aus heterogenen Dateien oder Bearbeitung von wiederkehrenden E-Mails.
Der erste Schritt besteht also darin, die bestehenden Prozesse zu analysieren. Sie müssen verstehen, wie die Teams tatsächlich arbeiten: Wo zirkulieren die Daten, welche Tools werden verwendet, wo gibt es doppelte Eingaben, manuelle Anpassungen, Informationsverluste oder Excel-Abhängigkeiten.
Diese Kartierungsphase ist entscheidend, denn sie zeigt, wo es betriebliche Reibungspunkte gibt und wo KI unmittelbare Vorteile bringen kann, ohne die Organisationen grundlegend zu verändern.
Der zweite Schritt besteht darin, die Datenkette minimal zu strukturieren. Selbst eine leistungsfähige KI liefert schwache Ergebnisse, wenn sie sich auf inkohärente, verstreute oder nicht regierte Daten stützt. Man muss nicht sofort eine komplexe Architektur aufbauen, aber man braucht eine verlässliche Grundlage: zentralisierte Daten, gemeinsame Definitionen und minimale Validierungsregeln.
Sobald diese Grundlage geschaffen ist, wird es möglich, einige gezielte Anwendungsfälle zu starten, die drei Merkmale aufweisen: begrenzter Umfang, messbarer Wert und geringes operationelles Risiko.
Die effektivsten Projekte sind oft sehr pragmatisch: Automatisierung von Memo-Zusammenfassungen, Extraktion von Informationen aus einem Datenraum, Vorbereitung von LP-Reportings, Unterstützung bei der Literatursuche oder Strukturierung von KPIs für Beteiligungen.
Der klassische Fehler besteht darin, eine globale KI-Strategie zu entwickeln, bevor die Daten- und Betriebsgrundlagen stabilisiert sind. Umgekehrt sind diejenigen Fonds erfolgreich, die schrittweise aufbauen: Strukturierung der Daten, erste geschäftliche Anwendungsfälle, Kompetenzaufbau der Teams und dann Industrialisierung.
Die KI muss als eine Beschleunigungsschicht über einer bereits beherrschten Organisation betrachtet werden. Ohne ein solides Fundament verstärkt sie die bestehenden Schwächen. Mit einer strukturierten Datenkette und einem klaren Rahmen für die Nutzung wird sie zu einem äußerst mächtigen operativen Hebel.
Welche neuen Rollen müssen in einem Fonds mit KI und Data entstehen?
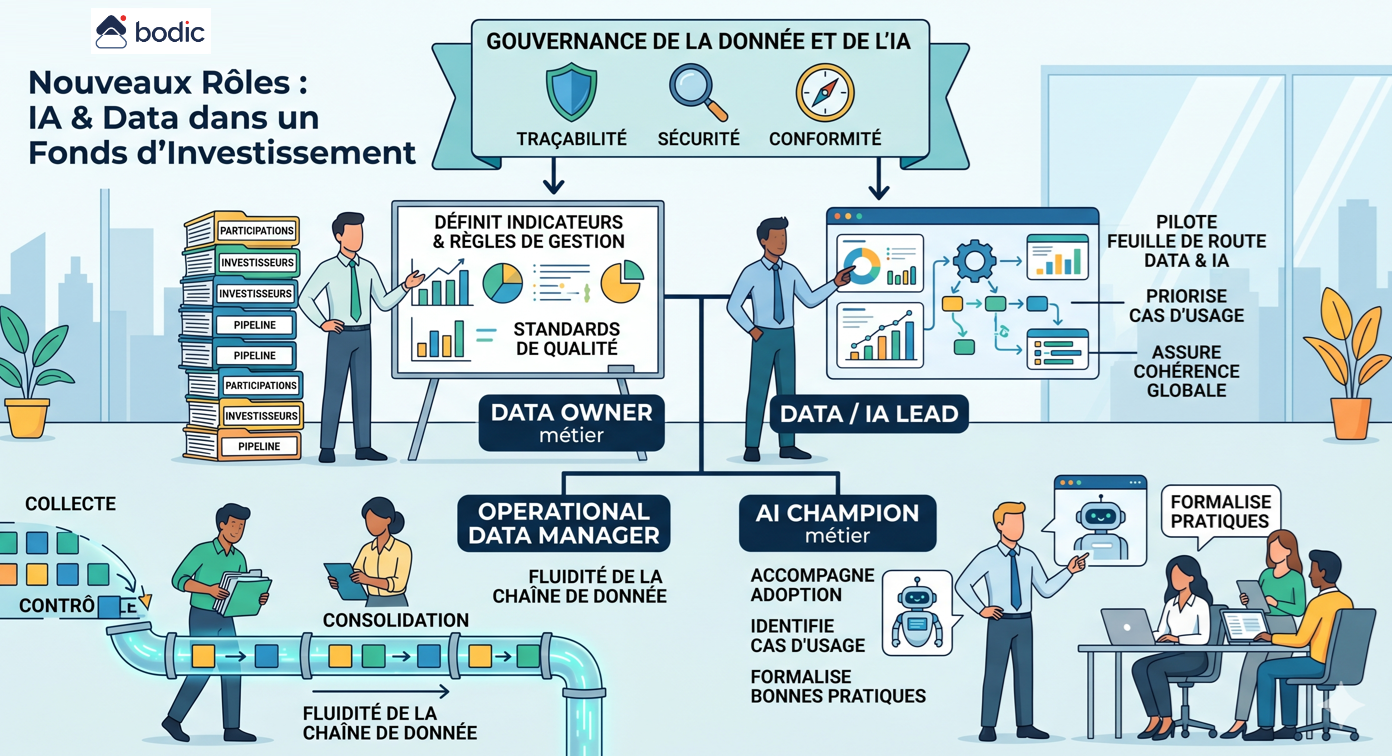
Die Einführung von KI und Data in einem Fonds führt nicht zu einem abrupten Bruch in den Berufen, sondern lässt neue Rollen rund um die Strukturierung der Daten, die Governance und die operative Nutzung entstehen.
Die erste Schlüsselrolle ist die des fachlichen Data Owners. Er trägt die Verantwortung für einen kritischen Datenumfang, z. B. Beteiligungen, Investoren oder die Pipeline. Er definiert die Indikatoren, die Verwaltungsregeln, die erwarteten Formate und die Qualitätsstandards. Ohne diese Rolle bleiben die Daten diffus und schwer verwertbar.
Die zweite Rolle ist die des Data / AI Lead. Er steuert die Data- und AI-Roadmap des Fonds, priorisiert die Anwendungsfälle, entscheidet über die Wahl der Tools und gewährleistet die globale Kohärenz. Er fungiert als Konvergenzpunkt zwischen den Investmentteams, dem Middle Office, der IR und den Unterstützungsfunktionen.
Eine dritte Rolle entsteht rund um den Operational Data Manager. Er befindet sich im Zentrum der Operationen, häufig im Middle Office, und stellt sicher, dass die Datenströme korrekt gesammelt, kontrolliert, konsolidiert und verbreitet werden. Er ist für die operative Qualität und den reibungslosen Ablauf der Datenkette verantwortlich.
Mit der KI entsteht auch eine spezifischere Rolle des KI-Berufschampions. Dieses Profil muss nicht unbedingt technisch sein, aber es beherrscht die Werkzeuge und ihre Nutzung. Es begleitet die Teams bei der Einführung, identifiziert relevante Anwendungsfälle und formalisiert bewährte Verfahren, insbesondere in Bezug auf die Überwachung und die Grenzen von KI-Agenten.
Schließlich wird eine übergreifende Rolle der Daten- und KI-Governance unerlässlich. Sie deckt die Themen Rückverfolgbarkeit, Sicherheit, Einhaltung und Kontrolle ab. In einem LP- und Regulierungskontext wird die Fähigkeit, Daten oder Entscheidungen zu erklären, genauso wichtig wie sie zu produzieren.
Es ist nicht notwendig, sofort ein dediziertes Team zu strukturieren. In den meisten Fonds entstehen diese Rollen allmählich aus den bestehenden Teams. Die Herausforderung besteht darin, die Verantwortlichkeiten zu identifizieren, den Umfang zu klären und einen gezielten Kompetenzaufbau zu strukturieren.
Der Schlüsselpunkt bleibt die fachliche Verankerung. Diese Rollen dürfen nicht in einer rein technischen Logik isoliert werden, sondern müssen in den Kern der Investitions- und Verwaltungsprozesse integriert werden. Es ist diese Nähe, die es ermöglicht, Daten in einen echten Leistungshebel zu verwandeln.
Wie kann KI die Beziehung zu Investoren und IR-Teams konkret verbessern?
KI kann die Beziehungen zu Anlegern und IR-Teams konkret verbessern, wenn sie als Hebel für mehr Zuverlässigkeit und Konsistenz eingesetzt wird und nicht als Werkzeug zur automatisierten Produktion von Nachrichten.
IR-Teams sehen sich mit einer wachsenden Anforderung konfrontiert: Sie müssen schneller reagieren, genaue, einheitliche und kontextbezogene Informationen liefern und sich gleichzeitig an sehr unterschiedliche Anlegerprofile anpassen. In diesem Zusammenhang kann die KI eine strukturierende Rolle spielen.
Konkret ermöglicht sie die Erstellung von Zusammenfassungen aus internen Berichten, die Neuformulierung von Inhalten entsprechend dem Kenntnisstand des Empfängers, das schnelle Auffinden von Informationen in der Historie des Datenaustauschs oder in einem Datenraum und die Verbesserung der Gesamtkohärenz der versendeten Dokumente. Sie kann auch die Erstellung standardisierter Antworten (FAQs, Standard-E-Mails) unterstützen, wobei ein hohes Maß an redaktioneller Qualität erhalten bleibt.
Der eigentliche Beitrag der KI liegt jedoch nicht in der Ausführungsgeschwindigkeit. Er liegt in der Fähigkeit, Nachrichten aneinander auszurichten. Eine qualitativ hochwertige IR-Kommunikation beruht auf einzelnen, zuverlässigen Daten, die von den Teams geteilt werden. Wenn die KI an fragmentierte oder schlecht regierte Quellen angeschlossen ist, verstärkt sie Inkonsistenzen, anstatt sie zu korrigieren.
Die Herausforderung besteht also darin, die KI in einer kontrollierten Datenkette zu verankern: gleiche Zahlen für BI, Reporting und Investorenkommunikation, Nachvollziehbarkeit der Quellen und systematische redaktionelle Kontrolle vor dem Versand. In diesem Rahmen wird die KI zu einem mächtigen Hilfsinstrument, um die Kommunikation zu strukturieren, zu harmonisieren und abzusichern.
Die richtige Balance besteht darin, KI zur Vorbereitung und Verlässlichkeit von Inhalten einzusetzen, während die Verantwortung für Ton, Kontext und Beziehung bei den KI-Teams verbleibt. Es ist diese Kombination, die sowohl die operative Effizienz als auch das Vertrauen der Anleger steigert.
Wie kann man die Teams eines Fonds effektiv in KI schulen, ohne in eine zu theoretische Akkulturation zu verfallen?
Die Teams eines Fonds effektiv in KI zu schulen, bedeutet nicht, theoretisches Wissen zu vermitteln, sondern konkrete Arbeitspraktiken umzuwandeln.
Eine sinnvolle Schulung beginnt immer mit den realen Situationen, denen die Teams begegnen. Investmentprofis brauchen keinen allgemeinen Diskurs über KI, sondern ein operatives Verständnis: was das Tool tatsächlich ermöglicht, wo seine Grenzen liegen und unter welchen Bedingungen es eingesetzt werden kann, ohne die Stringenz der Prozesse zu verschlechtern.
Das bedeutet, dass die Ansätze segmentiert werden müssen. Die Bedürfnisse eines Partners, eines Analysten, eines IR-, Compliance-, Middle-Office- oder ESG-Teams sind grundverschieden. Eine wirksame Schulung beruht daher auf einer gemeinsamen Grundlage (Grundsätze, Risiken, bewährte Praktiken), die durch gezielte Anwendungsfälle ergänzt wird: Analyse eines Investment Memos, Zusammenfassung eines Information Memorandums, Erforschung eines Datenraums, Vorbereitung eines Ausschusses, Sektorscreening oder Bewältigung eines komplexen Austauschs mit einem LP.
Der Schlüssel liegt in der unmittelbaren Anwendbarkeit. Jedes Modul muss es ermöglichen, am nächsten Tag mit sichtbaren und messbaren Gewinnen zu handeln. Das ist es, was eine Akkulturation in eine tatsächliche Übernahme verwandelt.
Schulungen können jedoch nicht als einmaliges Ereignis gedacht werden. Die Modelle entwickeln sich weiter, die Werkzeuge ändern sich, die Nutzungen werden klarer und die Risiken verlagern sich. Ein effektiver Ansatz ist langfristig angelegt: anfängliche Sensibilisierung, praktische Workshops nach Berufen, Erfahrungsaustausch unter Gleichgesinnten und kontinuierliche Begleitung zur Anpassung der Praktiken.
Und schließlich ein oft unterschätzter Punkt: Die Ausbildung in KI bedeutet auch die Ausbildung in Unterscheidungsfähigkeit. Zu wissen, wann man das Werkzeug benutzt, wann man ihm misstraut und wie man seine Ergebnisse kontrolliert, ist genauso wichtig wie das Wissen, wie man es benutzt.
Das richtige Instrumentarium kombiniert also Pädagogik, Praxis und Iteration. Es ist diese Logik, die es ermöglicht, KI dauerhaft in den Prozessen eines Fonds zu verankern, ohne in einen theoretischen Ansatz zu verfallen, der von der Praxis abgekoppelt ist.
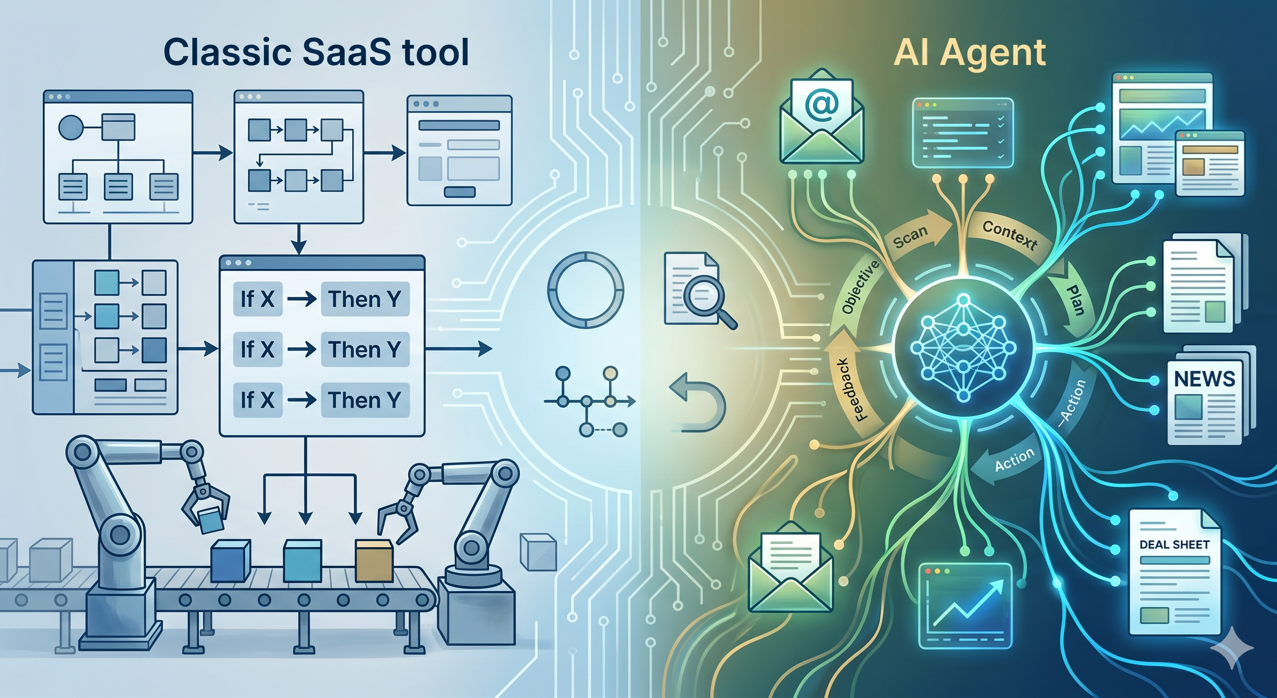
Was ist ein KI-Agent im Zusammenhang mit einem Fonds und wie unterscheidet er sich von einem herkömmlichen SaaS-Tool?
Ein klassischer SaaS führt vorprogrammierte Aktionen aus: Wenn X, dann Y. Ein KI-Agent hingegen erhält ein Ziel, versteht den Kontext, plant seine Schritte und führt eine Abfolge von Aktionen aus, indem er sich an die Daten anpasst, auf die er stößt. Diese Autonomie ist sein Interesse und sein Risiko.
In einem Fonds sind die für einen Agenten relevanten Anwendungsfälle gut gerahmt: Bearbeitung von Lieferanten-E-Mails, Anreicherung einer Deal-Karte, automatische Vorbereitung eines Komitee-Pakets anhand eines Datenraums, Überwachung von Signalen über Zielunternehmen. Schlecht gerahmte Fälle (Treffen einer Investitionsentscheidung, Senden einer Mitteilung an einen LP ohne Korrekturlesen) sind keine Fälle für Agenten, sondern Fälle für assistierte Menschen.
Ein guter Agent hat vier Eigenschaften: einen klaren Umfang, menschliche Aufsicht bei jedem sensiblen Schritt, vollständige Nachvollziehbarkeit und Umkehrbarkeit im Falle eines unerwarteten Verhaltens. Bodic entwickelt seine Agenten im Rahmen seiner maßgeschneiderten Entwicklungen nach diesen Grundsätzen.
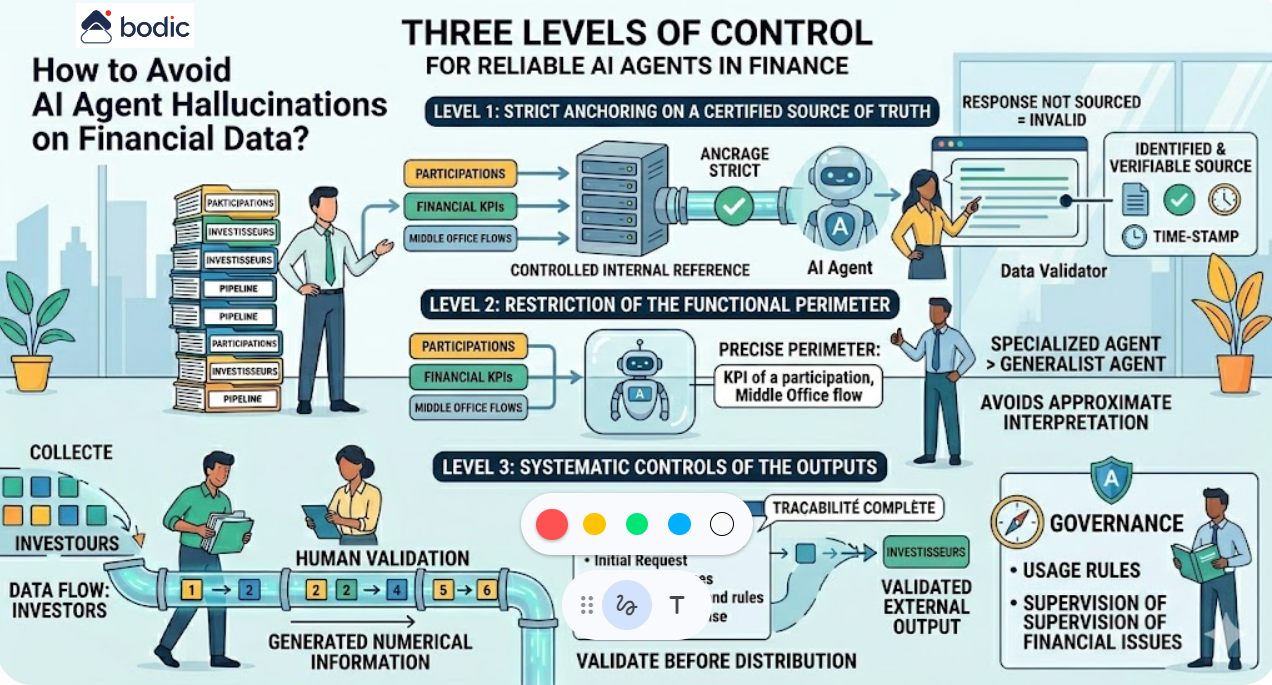
Wie können Halluzinationen eines KI-Agenten bei Finanzdaten verhindert werden?
Halluzinationen sind das größte Risiko beim Einsatz von KI-Agenten im Finanzkontext. Sie sind nicht auf zufällige Fehler zurückzuführen, sondern auf ein strukturelles Verhalten der Modelle, wenn ihnen keine zuverlässigen oder ausreichend eingeschränkten Informationen zur Verfügung stehen.
Dieses Risiko lässt sich durch drei Kontrollebenen stark reduzieren.
Die erste ist die strikte Verankerung an einer zertifizierten Wahrheitsquelle. Der Agent darf sich nicht auf allgemeines Wissen oder implizite Daten stützen, sondern nur auf ein kontrolliertes internes Referenzsystem. Jede Antwort muss mit einer identifizierbaren, zugänglichen und überprüfbaren Quelle verknüpft sein. Eine nicht quellenbasierte Antwort sollte standardmäßig als ungültig betrachtet werden.
Die zweite Ebene ist die Beschränkung des funktionalen und informationellen Umfangs. Ein Agent muss in einem bestimmten Bereich mit einem begrenzten und kontrollierten Datensatz tätig werden. Je breiter der Umfang, desto größer ist das Risiko einer ungefähren Interpretation. In der Praxis ist ein Agent, der auf eine Untermenge von Finanzdaten spezialisiert ist, z. B. die KPIs einer Beteiligung oder die Middle-Office-Feeds, signifikant zuverlässiger als ein generalistischer Agent.
Die dritte Ebene ist die Einführung systematischer Kontrollen der Outputs. Alle Zahleninformationen, die für den externen Gebrauch bestimmt sind, insbesondere für Investoren, müssen einer menschlichen Validierung unterzogen werden. Diese Validierung muss sich auf eine vollständige Rückverfolgbarkeit stützen: ursprüngliche Anfrage, mobilisierte Quellen, angewandte Transformationen und generierte Antwort.
Über diese Grundsätze hinaus spielt die technische Architektur eine entscheidende Rolle. Ein strukturierter Ansatz besteht darin, die KI-Schicht von den Rohdaten zu isolieren, ein zentrales Repository zu verwenden und den Agenten nur validierte Daten zu präsentieren. So lässt sich genau kontrollieren, was der Agent sehen und verwenden kann.
Schließlich ist es wichtig, Halluzinationen als ein Thema der Governance zu behandeln und nicht nur als ein technisches Problem. Das bedeutet, Nutzungsregeln, Verantwortungsebenen und Aufsichtsmechanismen zu definieren, die den finanziellen Herausforderungen angemessen sind.
Ein zuverlässiger Agent ist nicht derjenige, der "gut antwortet", sondern derjenige, bei dem jede Antwort erklärt, zurückverfolgt und verifiziert werden kann.
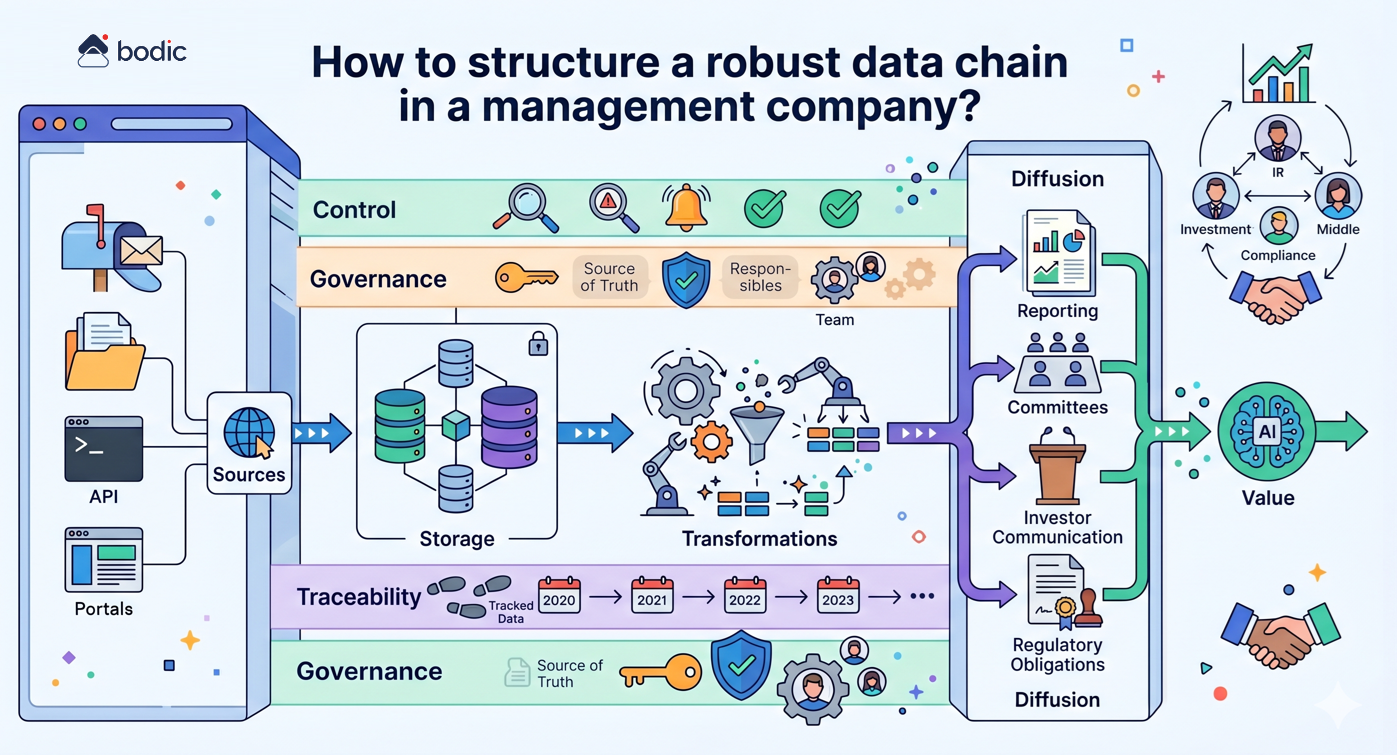
Wie strukturiert man eine robuste Datenkette in einer Verwaltungsgesellschaft?
Die Strukturierung einer robusten Datenkette in einer Verwaltungsgesellschaft besteht darin, den Informationsfluss von der Produktion bis zur Endnutzung explizit, kontrolliert und zuverlässig zu gestalten.
Konkret bedeutet dies, mehrere Schlüsselschritte zu formalisieren: Identifizierung der Datenquellen (E-Mails, Dateien, Portale, APIs), Definition der Speicherorte (interne Datenbanken, Data Warehouse, Business-Tools), Organisation der Transformationen (Bereinigung, Anreicherung, Konsolidierung) und dann Strukturierung der Verteilung an die Endnutzer (Reporting, Komitees, Anlegerkommunikation, regulatorische Verpflichtungen).
Eine robuste Datenkette beruht auf einigen grundlegenden Prinzipien.
Zunächst einmal muss jeder kritische Datensatz klar definiert sein: eine identifizierte Quelle, ein Referenzformat, eine Aktualisierungshäufigkeit und ein Verantwortlicher. Ohne diese Disziplin kommt es schnell zu Diskrepanzen zwischen Teams, Tools und Lieferungen.
Zweitens ist es von entscheidender Bedeutung, Redundanzen zu begrenzen. Die Vervielfachung von Excel-Dateien, lokalen Extraktionen oder parallelen Versionen führt zu Inkonsistenzen und schwächt das Vertrauen in die Zahlen. Ziel ist es, zu einer gemeinsamen, zugänglichen und kontrollierten "Quelle der Wahrheit" zu konvergieren.
Auch die Nachvollziehbarkeit ist zentral. Jede Zahl, die in einer Berichterstattung oder einem Ausschuss verwendet wird, muss mit ihrem Ursprung verbunden werden können, mit einer Historie der Umwandlungen. Dies wird kritisch, sobald die LP- oder regulatorischen Anforderungen steigen.
Schließlich beinhaltet eine robuste Kette auch Kontrollmechanismen: Validierungsregeln, Warnungen bei Anomalien, menschliche Aufsicht an sensiblen Punkten. Dieser Rahmen ermöglicht es, die Qualität zu sichern, ohne die Abläufe zu verlangsamen.
Die Herausforderung geht weit über die Technik hinaus. Eine gut strukturierte Datenkette verbessert die Qualität der Berichte, erleichtert die Zusammenarbeit zwischen den Teams (Investment, IR, Middle Office, Compliance), erhöht die Glaubwürdigkeit gegenüber den Anlegern und beschleunigt die Entscheidungsfindung.
Dies ist auch eine Grundvoraussetzung für den effektiven Einsatz von KI-Tools. Ohne strukturierte, zuverlässige und gesteuerte Daten verstärkt die KI bestehende Mängel, anstatt Werte zu schaffen.
Kann die Berichterstattung über Beteiligungen wirksam automatisiert werden?
Ja, die Automatisierung der Berichterstattung über Beteiligungen ist nicht nur möglich, sondern auch einer der unmittelbarsten Hebel für operative Verbesserungen in einem Fonds.
In den meisten Organisationen beruht der Prozess noch auf manuellen Erhebungen, heterogenen Dateien, die von den Beteiligungen übermittelt werden, und Konsolidierungen, die in Excel durchgeführt werden. Dieses Modell weist mehrere Schwachstellen auf: Abhängigkeit von nicht standardisierten Formaten, Fehlerrisiken bei der Anpassung, fehlende Rückverfolgbarkeit und hohe Produktionszeiten.
Eine wirksame Automatisierung hängt von der Strukturierung der Datenkette im Vorfeld ab.
Der erste Schritt ist die Standardisierung der Inputs. Dies bedeutet, dass ein gemeinsames Datenwörterbuch mit den Beteiligungen definiert werden muss, das klar definierte Indikatoren, erwartete Formate, explizite Berechnungsregeln und einen Zeitplan für die Rückführung enthält. Ohne diese Standardisierung bleibt jede Automatisierung unvollständig.
Zweiter Schritt: Organisieren Sie die Sammlung. Dies kann über spezielle Portale, strukturierte Templates oder Konnektoren erfolgen. Ziel ist es, Formatvariationen zu reduzieren und manuelle Eingriffe zu begrenzen.
Dritter Schritt: Die Kontrollen industrialisieren. Automatische Regeln ermöglichen die Erkennung von Inkonsistenzen, Variationsabweichungen, Reihenbrüchen oder Anomalien zwischen verbundenen Indikatoren. Diese Kontrollen müssen systematisch und nachvollziehbar sein.
Vierter Schritt: Zentralisierung in einer einzigen Wahrheitsquelle. Die konsolidierten Daten müssen direkt in die Reporting-, BI- und Investorenkommunikationstools eingespeist werden, um Doppelarbeit oder lokale Nachbearbeitung zu vermeiden.
In diesem Rahmen kann die Automatisierung die Produktion sichern, die Fristen verkürzen und die Zuverlässigkeit der Ergebnisse deutlich erhöhen.
Die Rolle der Teams ändert sich. Sie wechseln von einer Produktionslogik zu einer Kontroll- und Analyselogik. Die Herausforderung besteht nicht mehr darin, Daten zu konsolidieren, sondern sie zu interpretieren, schwache Signale zu erkennen und Entscheidungen vorzubereiten.
Schließlich bleibt der kritische Punkt die Governance. Eine Automatisierung ohne klare Regeln für Datenqualität, Verantwortlichkeiten und Validierungsprozesse kann die Zuverlässigkeit insgesamt verschlechtern. Die Automatisierung muss in einen strengen Rahmen eingebettet sein, der auf Kontrolle, Nachvollziehbarkeit und Konsistenz ausgerichtet ist.
Wie kann man KI zur Vorbereitung eines Investitionsausschusses einsetzen, ohne die Qualität des Urteils zu verschlechtern?
KI kann die Vorbereitung eines Anlageausschusses erheblich verbessern, sofern sie nicht das verschlechtert, was die Qualität einer Entscheidung ausmacht: die Klarheit der Argumentation, die Priorisierung von Informationen und die Solidität der Überzeugung.
Das Hauptrisiko ist klar erkannt: KI erhöht die Menge der verfügbaren Informationen: mehr Daten, mehr Szenarien, mehr Signale, ohne eine bessere Entscheidung zu garantieren. Diese Fülle kann sogar zu einer kognitiven Überlastung führen und die wirklich strukturierenden Punkte verwässern. Es ist daher von entscheidender Bedeutung, Informationsreichtum nicht mit der Qualität des Urteils zu verwechseln.
Der richtige Gebrauch besteht darin, die KI um den Entscheidungsprozess herum zu organisieren und nicht umgekehrt. Das bedeutet, dass die Schlüsselfragen, die in den Ausschüssen diskutiert werden, im Vorfeld identifiziert werden müssen und dann gezielte Zusammenfassungen erstellt werden, die so kalibriert sind, dass sie diese Fragen beleuchten, ohne nach Vollständigkeit zu streben. Ziel ist es, das Rauschen zu reduzieren, um das Signal zu verstärken.
KI ist besonders hilfreich bei der Vorbereitung dieser Materialien: Strukturierung eines Investitionsmemorandums, Zusammenfassung eines Datenraums, Abgleich verschiedener Informationsquellen oder Neuformulierung von Analysen, um deren Lesbarkeit zu verbessern. Sie sollte jedoch nicht anstelle der Teams zu Schlussfolgerungen kommen. Die Verantwortung für die Analyse und die Empfehlung bleibt beim Menschen.
Ein Schlüsselpunkt ist die Nachvollziehbarkeit. Jede Zahl oder Behauptung, die im Ausschuss verwendet wird, muss mit einer identifizierbaren Quelle in Verbindung gebracht werden können. KI kann bei der Strukturierung dieser Nachvollziehbarkeit helfen, muss sich aber auf eine zuverlässige und gesteuerte Datenkette stützen.
In Sitzungen ist ihre Rolle eher taktischer Natur: Sie soll schnell eine bestimmte Information finden, einen Punkt überprüfen und auf Wunsch ein alternatives Szenario erforschen. So eingesetzt, wird er zu einem unterstützenden Instrument, ohne die Entscheidungsdynamik zu beeinträchtigen.
Schließlich ist der richtige Leistungsindikator nicht die eingesparte Vorbereitungszeit, sondern die Qualität der getroffenen Entscheidungen. Eine richtig eingesetzte KI muss das Verständnis der Herausforderungen, die Robustheit des Austauschs und die Entscheidungsfähigkeit verbessern und nicht nur die Produktion von Dokumenten beschleunigen.
Wir verwenden Cookies, um Ihnen die beste Erfahrung auf unserer Website zu bieten. Sie können mehr über die von uns verwendeten Cookies erfahren oder sie in den Einstellungen deaktivieren.