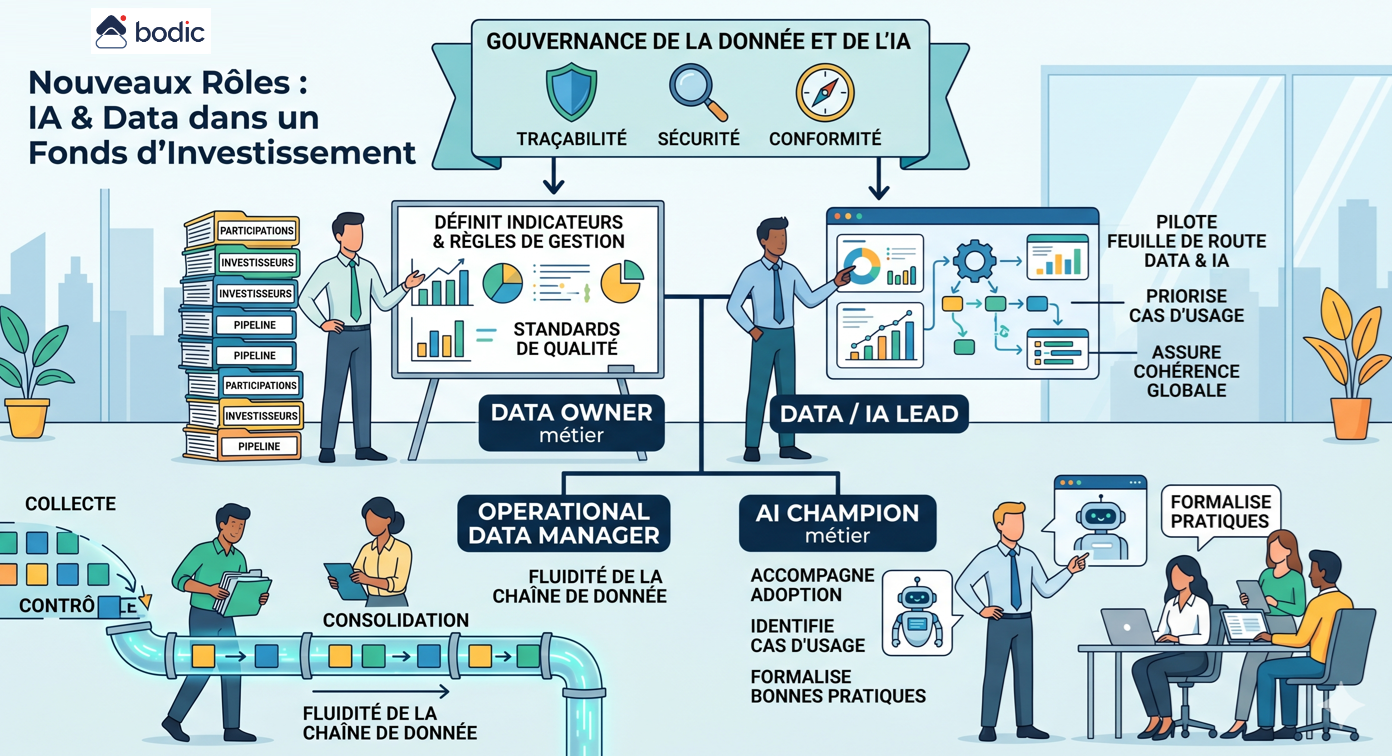
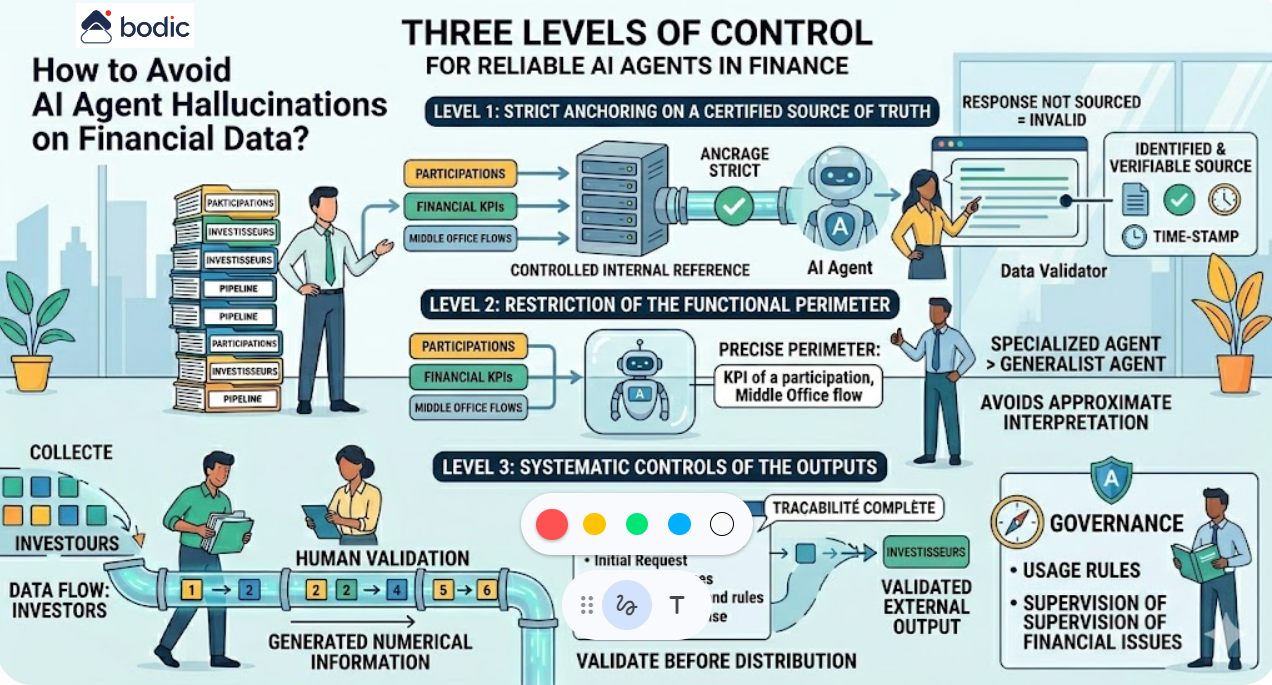
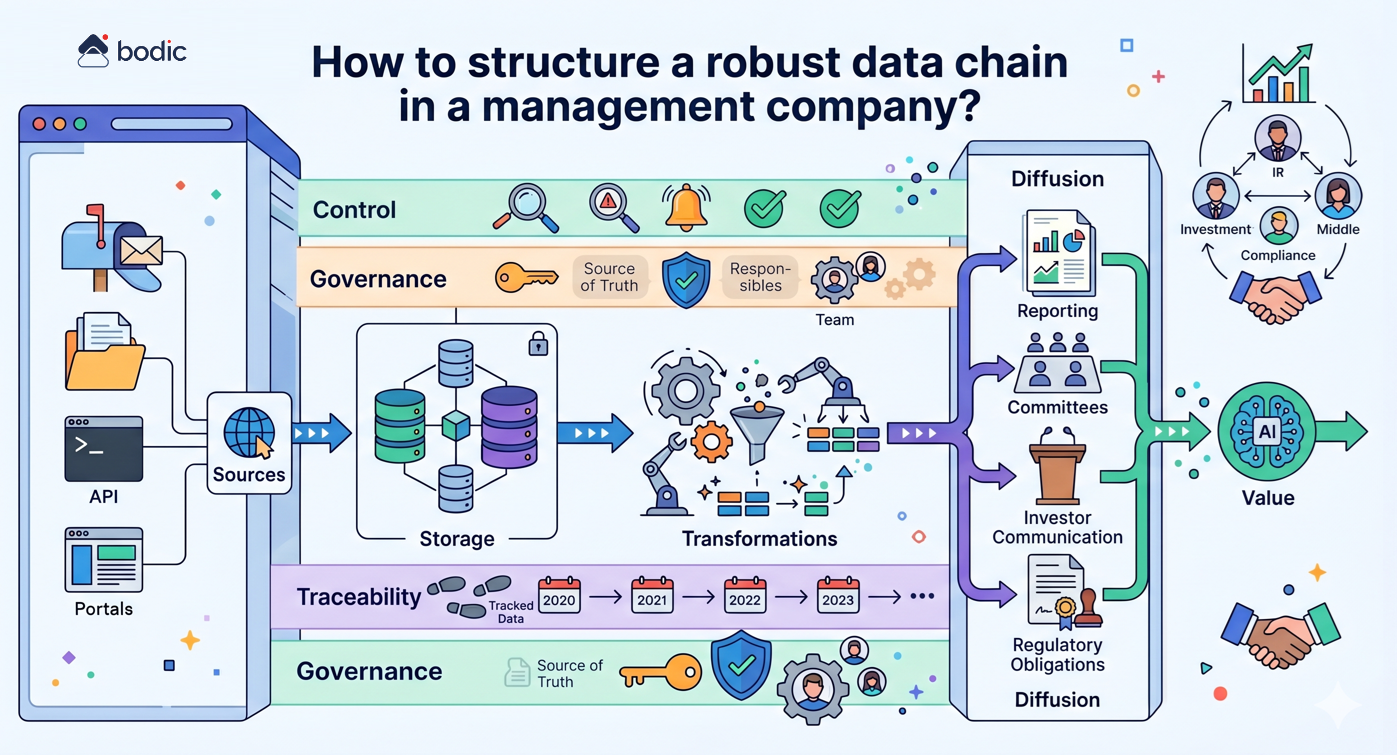
Where do you actually start with AI in a fund?
The question of where to start with AI in a fund is often approached from the wrong angle. The point is not to choose a tool, but to identify where AI can concretely improve operational efficiency, data quality or decision quality.
In the majority of asset management companies, the first gains are not to be found in complex or "spectacular" applications. Instead, they appear on repetitive, time-consuming tasks with little intellectual added value: consolidating reports, preparing summaries, searching for information in documents, producing reports, structuring data from heterogeneous files or processing recurring e-mails.
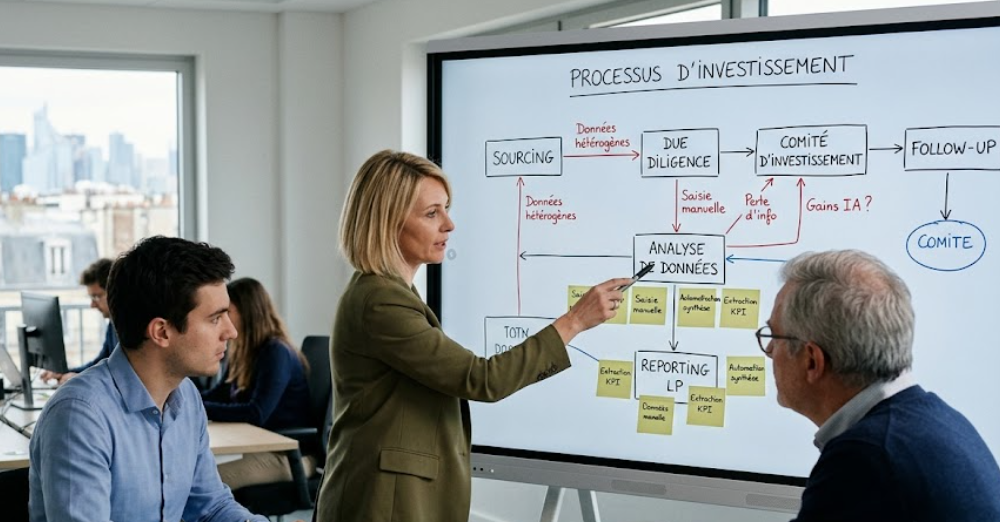
The first step is to analyze existing processes. We need to understand how teams actually work: where data flows, what tools are used, where there is double entry, manual reprocessing, loss of information or Excel dependencies.
This mapping phase is essential, as it identifies areas of operational friction and points where AI can bring immediate gain without profoundly changing organizations.
The second step is to structure the data chain to a minimum. Even high-performance AI produces weak results if it relies on inconsistent, dispersed or ungoverned data. You don't need to build a complex architecture right away, but you do need a reliable foundation: centralized data, common definitions and minimal validation rules.
Once this foundation has been laid, it's possible to launch a few targeted use cases, with three characteristics: limited scope, measurable value and low operational risk.
The most effective projects are often highly pragmatic: automating memo summaries, extracting information from a data room, preparing LP reports, assisting document research or structuring participative KPIs.
The classic mistake is to try to deploy a global AI strategy before having stabilized the data and operational fundamentals. Conversely, funds that move forward effectively are those that build progressively: structuring data, first business use cases, ramping up team skills, then industrialization.
AI should be thought of as a layer of acceleration on top of an already mastered organization. Without solid foundations, it amplifies existing weaknesses. With a structured data chain and well-defined uses, it becomes an extremely powerful operational lever.
In the majority of asset management companies, the first gains are not to be found in complex or "spectacular" applications. Instead, they appear on repetitive, time-consuming tasks with little intellectual added value: consolidating reports, preparing summaries, searching for information in documents, producing reports, structuring data from heterogeneous files or processing recurring e-mails.
The first step is to analyze existing processes. We need to understand how teams actually work: where data flows, what tools are used, where there is double entry, manual reprocessing, loss of information or Excel dependencies.
This mapping phase is essential, as it identifies areas of operational friction and points where AI can bring immediate gain without profoundly changing organizations.
The second step is to structure the data chain to a minimum. Even high-performance AI produces weak results if it relies on inconsistent, dispersed or ungoverned data. You don't need to build a complex architecture right away, but you do need a reliable foundation: centralized data, common definitions and minimal validation rules.
Once this foundation has been laid, it's possible to launch a few targeted use cases, with three characteristics: limited scope, measurable value and low operational risk.
The most effective projects are often highly pragmatic: automating memo summaries, extracting information from a data room, preparing LP reports, assisting document research or structuring participative KPIs.
The classic mistake is to try to deploy a global AI strategy before having stabilized the data and operational fundamentals. Conversely, funds that move forward effectively are those that build progressively: structuring data, first business use cases, ramping up team skills, then industrialization.
AI should be thought of as a layer of acceleration on top of an already mastered organization. Without solid foundations, it amplifies existing weaknesses. With a structured data chain and well-defined uses, it becomes an extremely powerful operational lever.