What is an AI agent in the context of a fund, and how is it different from a classic SaaS tool?
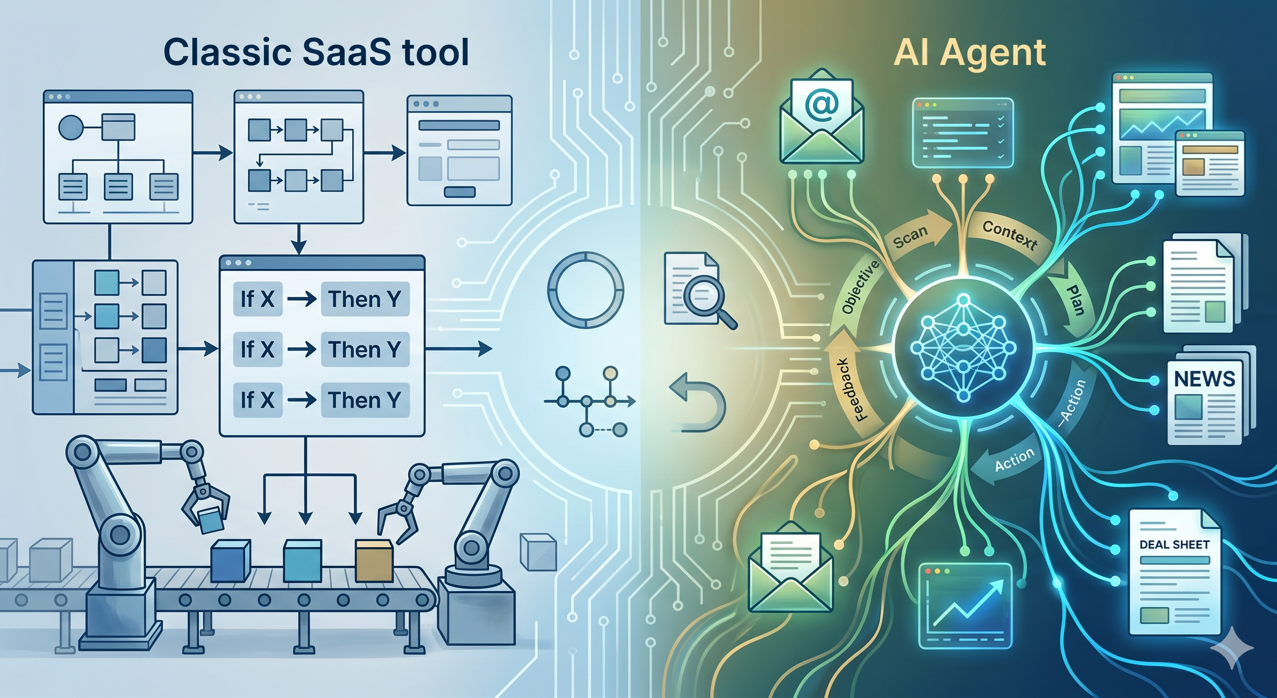
A classic SaaS executes pre-programmed actions: if X, then Y. An AI agent, on the other hand, receives an objective, understands the context, plans its steps and executes a sequence of actions, adapting to the data it encounters. This autonomy is both its interest and its risk.
In a fund, the relevant use cases for an agent are well-defined: processing supplier emails, enriching a deal sheet, automatically preparing a committee pack from a data room, monitoring signals on target companies. Ill-framed cases (making an investment decision, sending a communication to an LP without proofreading) are not cases for agents, they are cases for assisted humans.
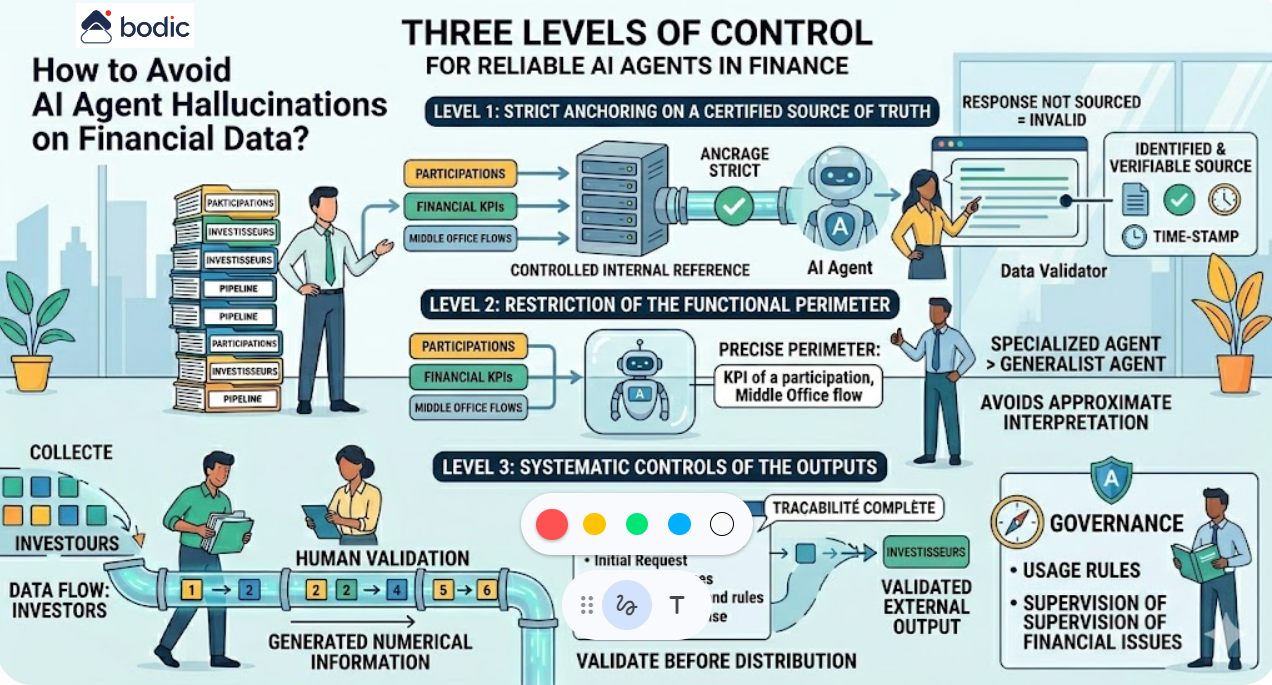
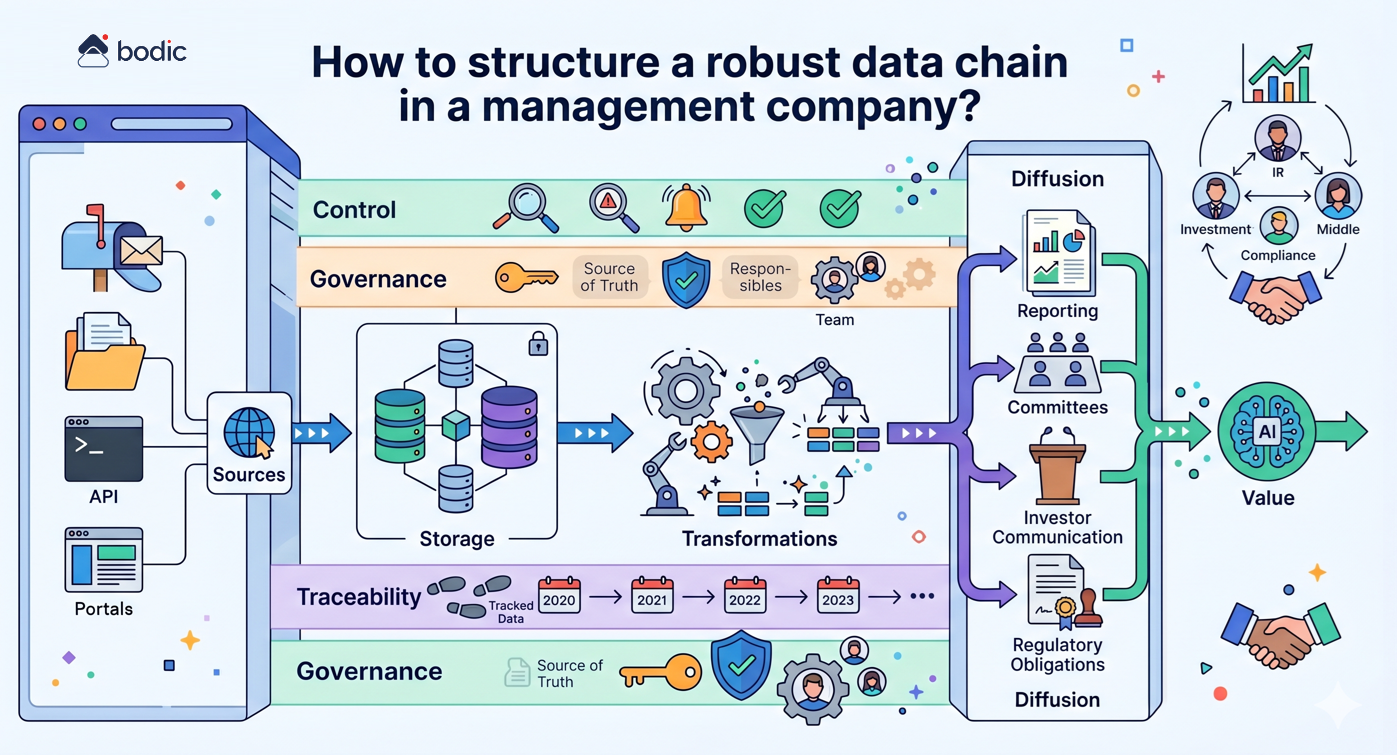
A good agent has four characteristics: a clear perimeter, human supervision at every sensitive stage, complete traceability, and reversibility in the event of unexpected behavior. Bodic develops its agents according to these principles as part of its customized developments.
In a fund, the relevant use cases for an agent are well-defined: processing supplier emails, enriching a deal sheet, automatically preparing a committee pack from a data room, monitoring signals on target companies. Ill-framed cases (making an investment decision, sending a communication to an LP without proofreading) are not cases for agents, they are cases for assisted humans.
A good agent has four characteristics: a clear perimeter, human supervision at every sensitive stage, complete traceability, and reversibility in the event of unexpected behavior. Bodic develops its agents according to these principles as part of its customized developments.