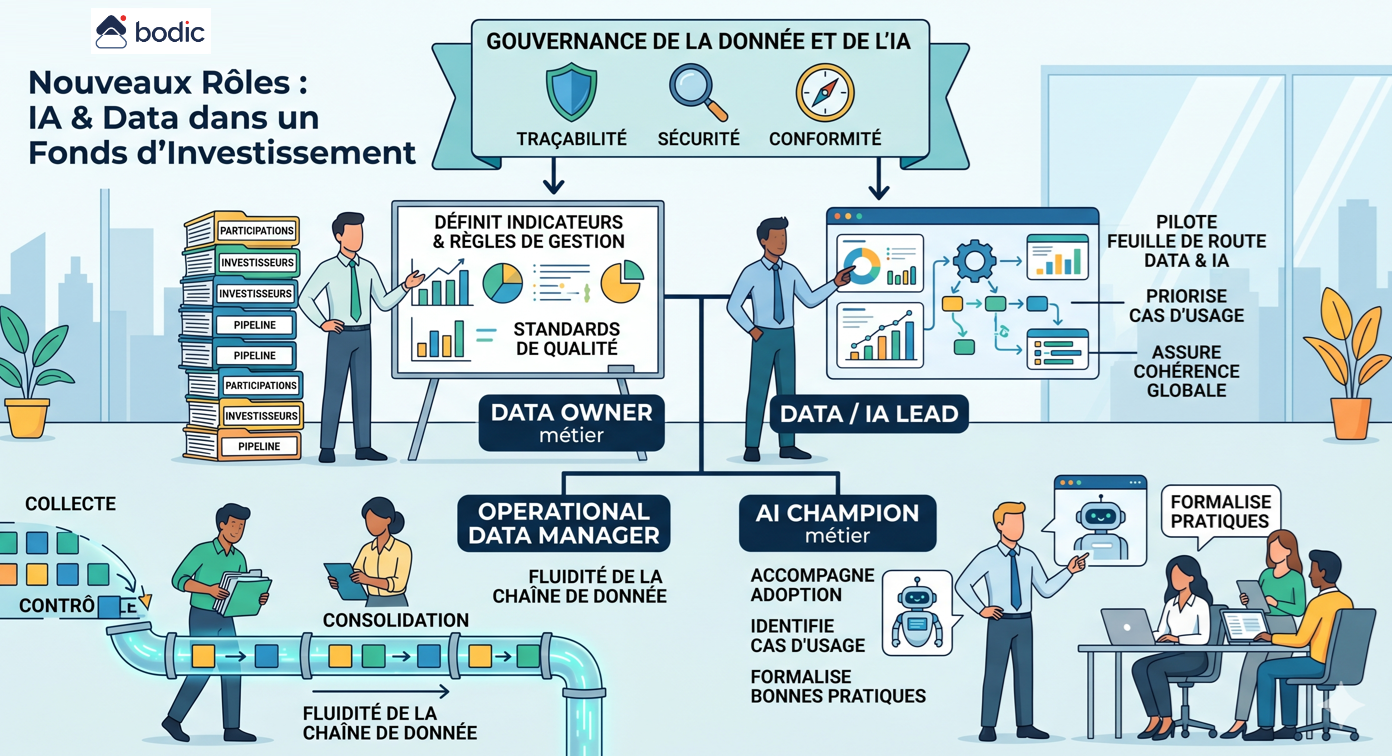
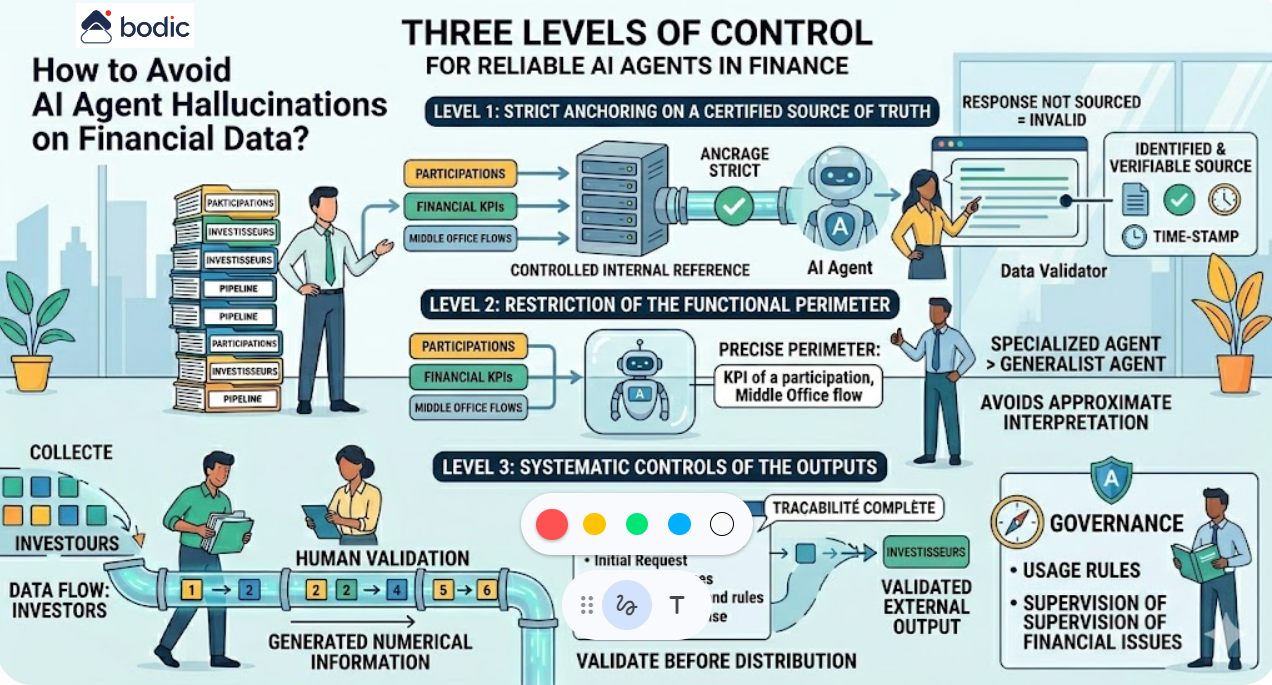
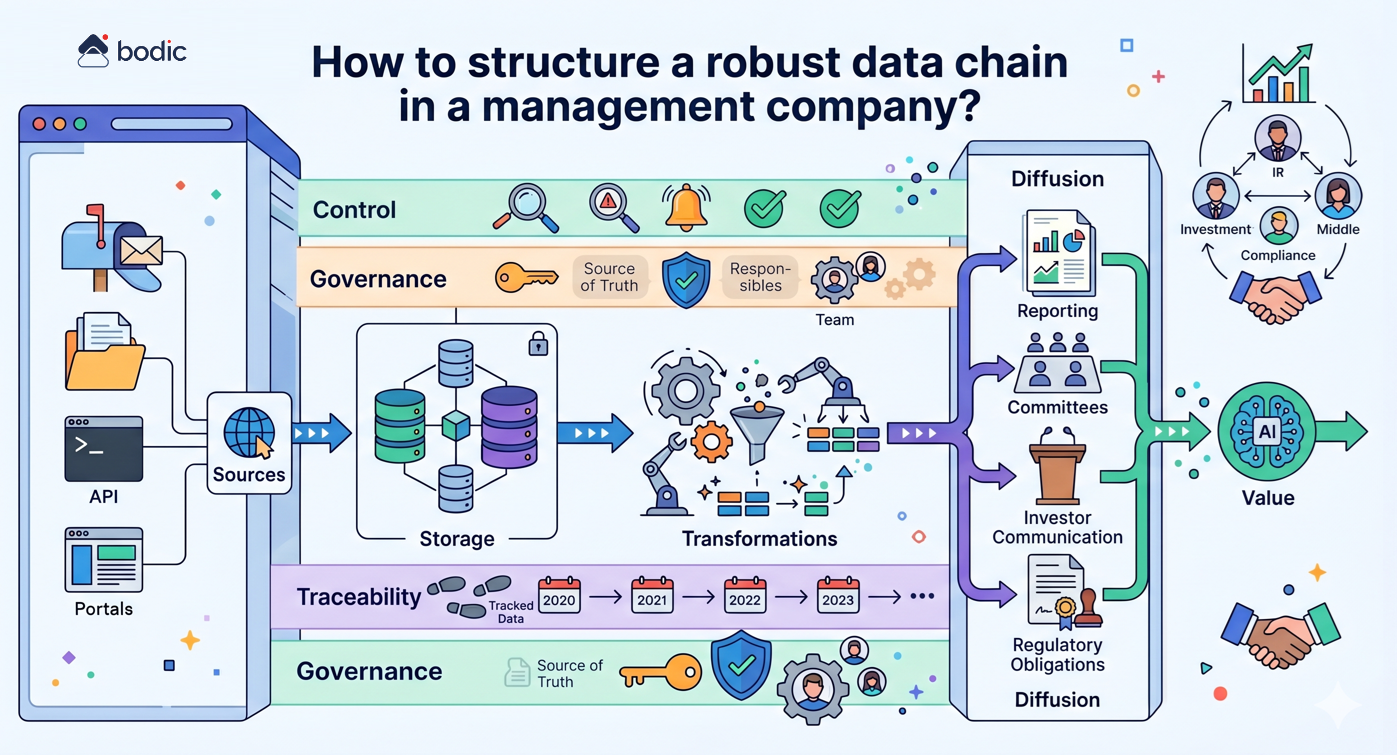
Wo soll man mit KI in einem Fonds konkret anfangen?
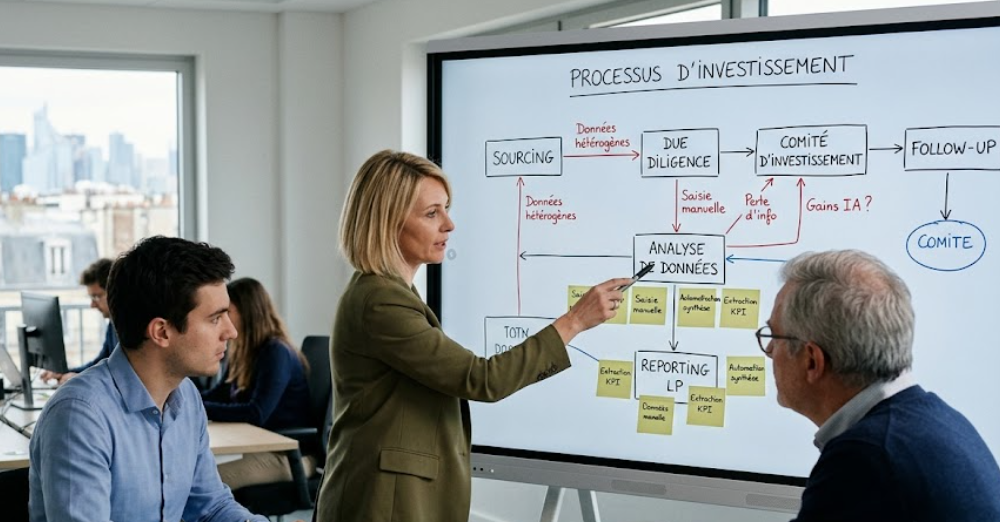
Die Frage, wo man mit KI in einem Fonds anfangen soll, wird oft aus dem falschen Blickwinkel angegangen. Es geht nicht darum, ein Werkzeug auszuwählen, sondern zu ermitteln, wo KI die betriebliche Effizienz, die Datenqualität oder die Entscheidungsqualität konkret verbessern kann.
In der Mehrzahl der Verwaltungsgesellschaften sind die ersten Gewinne nicht bei komplexen oder "spektakulären" Anwendungen zu verzeichnen. Sie treten vielmehr bei sich wiederholenden, zeitraubenden Aufgaben mit geringem intellektuellen Mehrwert auf: Konsolidierung von Berichten, Erstellung von Zusammenfassungen, Suche nach Informationen in Dokumenten, Erstellung von Berichten, Strukturierung von Daten aus heterogenen Dateien oder Bearbeitung von wiederkehrenden E-Mails.
Der erste Schritt besteht also darin, die bestehenden Prozesse zu analysieren. Sie müssen verstehen, wie die Teams tatsächlich arbeiten: Wo zirkulieren die Daten, welche Tools werden verwendet, wo gibt es doppelte Eingaben, manuelle Anpassungen, Informationsverluste oder Excel-Abhängigkeiten.
Diese Kartierungsphase ist entscheidend, denn sie zeigt, wo es betriebliche Reibungspunkte gibt und wo KI unmittelbare Vorteile bringen kann, ohne die Organisationen grundlegend zu verändern.
Der zweite Schritt besteht darin, die Datenkette minimal zu strukturieren. Selbst eine leistungsfähige KI liefert schwache Ergebnisse, wenn sie sich auf inkohärente, verstreute oder nicht regierte Daten stützt. Man muss nicht sofort eine komplexe Architektur aufbauen, aber man braucht eine verlässliche Grundlage: zentralisierte Daten, gemeinsame Definitionen und minimale Validierungsregeln.
Sobald diese Grundlage geschaffen ist, wird es möglich, einige gezielte Anwendungsfälle zu starten, die drei Merkmale aufweisen: begrenzter Umfang, messbarer Wert und geringes operationelles Risiko.
Die effektivsten Projekte sind oft sehr pragmatisch: Automatisierung von Memo-Zusammenfassungen, Extraktion von Informationen aus einem Datenraum, Vorbereitung von LP-Reportings, Unterstützung bei der Literatursuche oder Strukturierung von KPIs für Beteiligungen.
Der klassische Fehler besteht darin, eine globale KI-Strategie zu entwickeln, bevor die Daten- und Betriebsgrundlagen stabilisiert sind. Umgekehrt sind diejenigen Fonds erfolgreich, die schrittweise aufbauen: Strukturierung der Daten, erste geschäftliche Anwendungsfälle, Kompetenzaufbau der Teams und dann Industrialisierung.
Die KI muss als eine Beschleunigungsschicht über einer bereits beherrschten Organisation betrachtet werden. Ohne ein solides Fundament verstärkt sie die bestehenden Schwächen. Mit einer strukturierten Datenkette und einem klaren Rahmen für die Nutzung wird sie zu einem äußerst mächtigen operativen Hebel.
In der Mehrzahl der Verwaltungsgesellschaften sind die ersten Gewinne nicht bei komplexen oder "spektakulären" Anwendungen zu verzeichnen. Sie treten vielmehr bei sich wiederholenden, zeitraubenden Aufgaben mit geringem intellektuellen Mehrwert auf: Konsolidierung von Berichten, Erstellung von Zusammenfassungen, Suche nach Informationen in Dokumenten, Erstellung von Berichten, Strukturierung von Daten aus heterogenen Dateien oder Bearbeitung von wiederkehrenden E-Mails.
Der erste Schritt besteht also darin, die bestehenden Prozesse zu analysieren. Sie müssen verstehen, wie die Teams tatsächlich arbeiten: Wo zirkulieren die Daten, welche Tools werden verwendet, wo gibt es doppelte Eingaben, manuelle Anpassungen, Informationsverluste oder Excel-Abhängigkeiten.
Diese Kartierungsphase ist entscheidend, denn sie zeigt, wo es betriebliche Reibungspunkte gibt und wo KI unmittelbare Vorteile bringen kann, ohne die Organisationen grundlegend zu verändern.
Der zweite Schritt besteht darin, die Datenkette minimal zu strukturieren. Selbst eine leistungsfähige KI liefert schwache Ergebnisse, wenn sie sich auf inkohärente, verstreute oder nicht regierte Daten stützt. Man muss nicht sofort eine komplexe Architektur aufbauen, aber man braucht eine verlässliche Grundlage: zentralisierte Daten, gemeinsame Definitionen und minimale Validierungsregeln.
Sobald diese Grundlage geschaffen ist, wird es möglich, einige gezielte Anwendungsfälle zu starten, die drei Merkmale aufweisen: begrenzter Umfang, messbarer Wert und geringes operationelles Risiko.
Die effektivsten Projekte sind oft sehr pragmatisch: Automatisierung von Memo-Zusammenfassungen, Extraktion von Informationen aus einem Datenraum, Vorbereitung von LP-Reportings, Unterstützung bei der Literatursuche oder Strukturierung von KPIs für Beteiligungen.
Der klassische Fehler besteht darin, eine globale KI-Strategie zu entwickeln, bevor die Daten- und Betriebsgrundlagen stabilisiert sind. Umgekehrt sind diejenigen Fonds erfolgreich, die schrittweise aufbauen: Strukturierung der Daten, erste geschäftliche Anwendungsfälle, Kompetenzaufbau der Teams und dann Industrialisierung.
Die KI muss als eine Beschleunigungsschicht über einer bereits beherrschten Organisation betrachtet werden. Ohne ein solides Fundament verstärkt sie die bestehenden Schwächen. Mit einer strukturierten Datenkette und einem klaren Rahmen für die Nutzung wird sie zu einem äußerst mächtigen operativen Hebel.