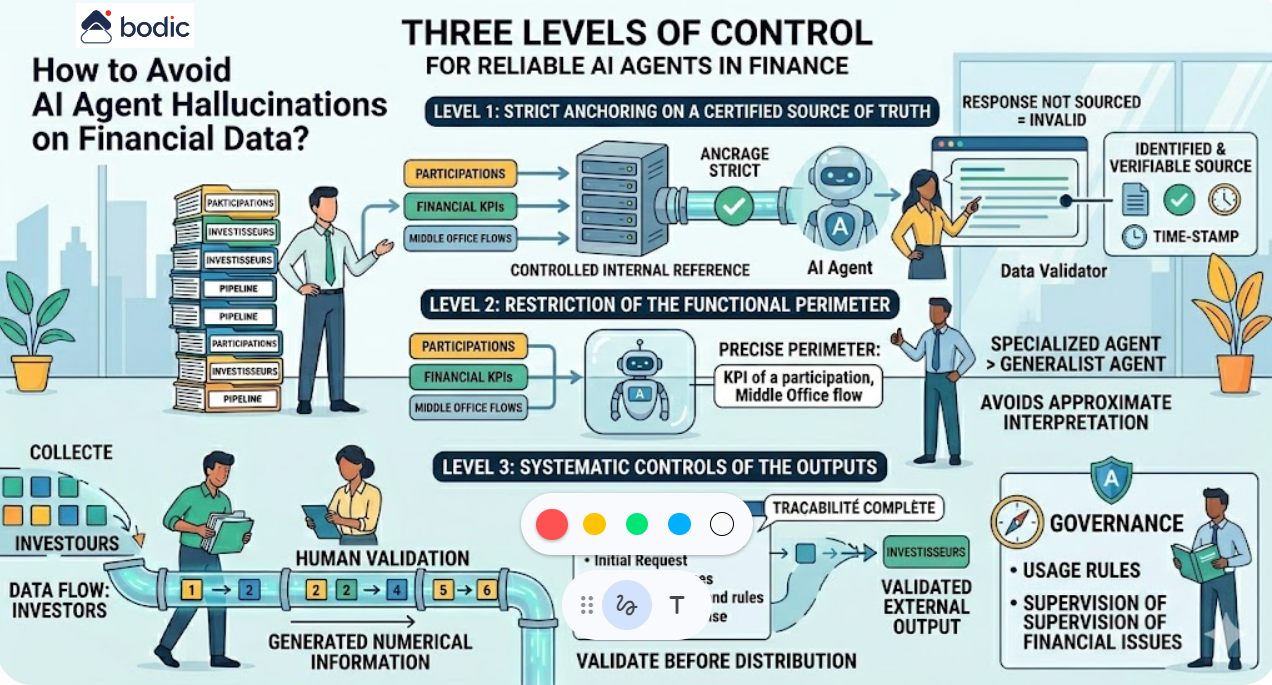
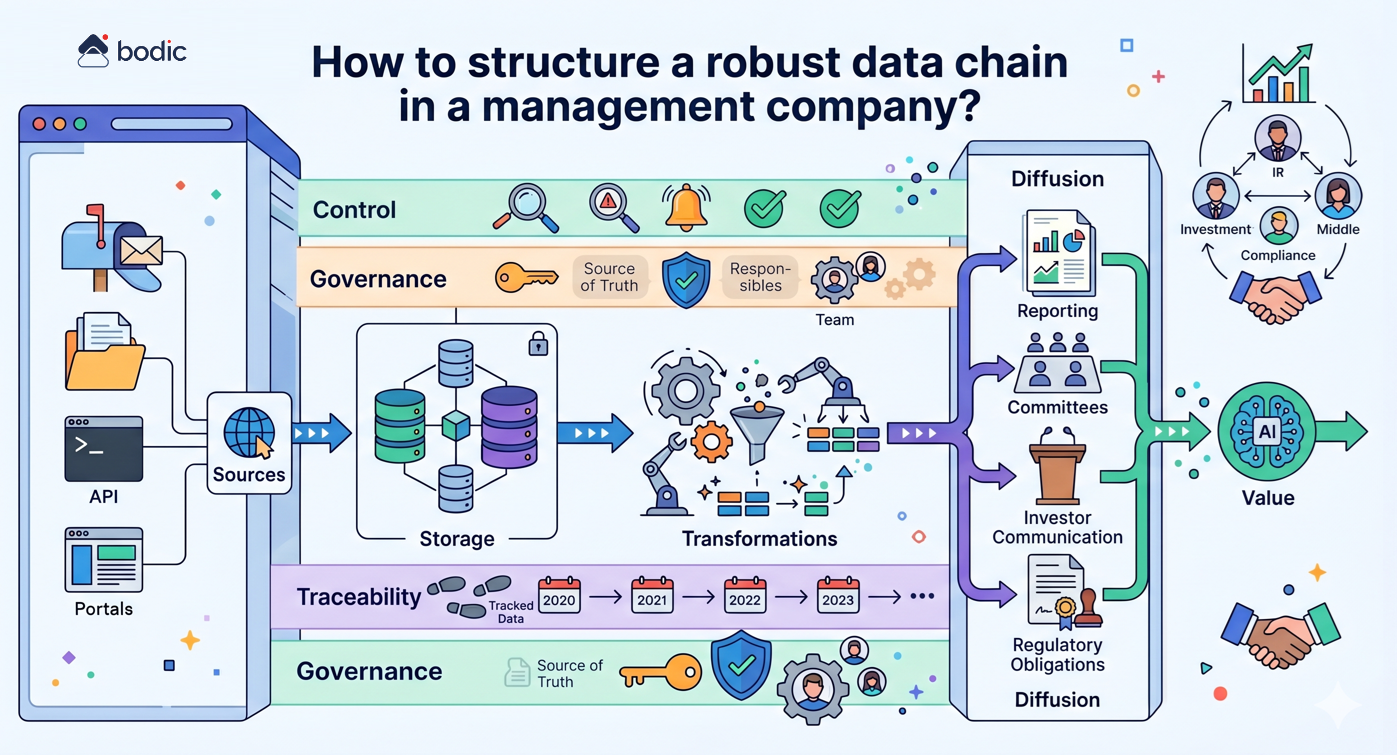
Was ist ein KI-Agent im Zusammenhang mit einem Fonds und wie unterscheidet er sich von einem herkömmlichen SaaS-Tool?
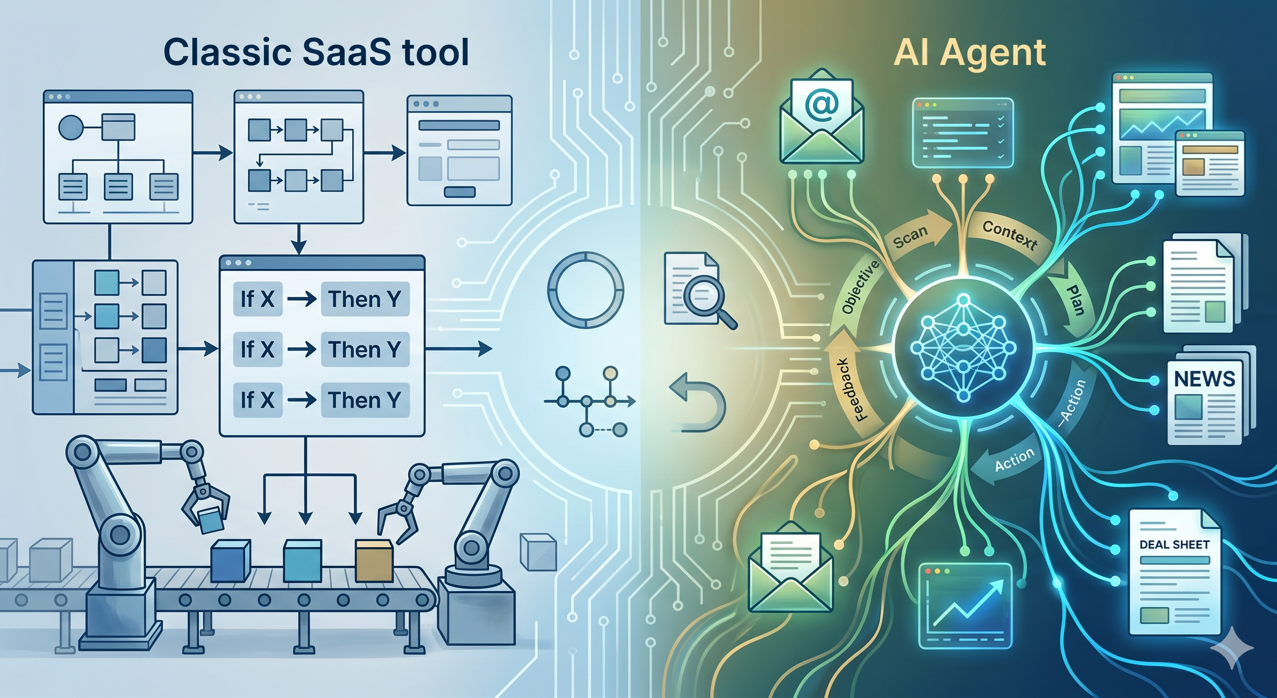
Ein klassischer SaaS führt vorprogrammierte Aktionen aus: Wenn X, dann Y. Ein KI-Agent hingegen erhält ein Ziel, versteht den Kontext, plant seine Schritte und führt eine Abfolge von Aktionen aus, indem er sich an die Daten anpasst, auf die er stößt. Diese Autonomie ist sein Interesse und sein Risiko.
In einem Fonds sind die für einen Agenten relevanten Anwendungsfälle gut gerahmt: Bearbeitung von Lieferanten-E-Mails, Anreicherung einer Deal-Karte, automatische Vorbereitung eines Komitee-Pakets anhand eines Datenraums, Überwachung von Signalen über Zielunternehmen. Schlecht gerahmte Fälle (Treffen einer Investitionsentscheidung, Senden einer Mitteilung an einen LP ohne Korrekturlesen) sind keine Fälle für Agenten, sondern Fälle für assistierte Menschen.
Ein guter Agent hat vier Eigenschaften: einen klaren Umfang, menschliche Aufsicht bei jedem sensiblen Schritt, vollständige Nachvollziehbarkeit und Umkehrbarkeit im Falle eines unerwarteten Verhaltens. Bodic entwickelt seine Agenten im Rahmen seiner maßgeschneiderten Entwicklungen nach diesen Grundsätzen.
In einem Fonds sind die für einen Agenten relevanten Anwendungsfälle gut gerahmt: Bearbeitung von Lieferanten-E-Mails, Anreicherung einer Deal-Karte, automatische Vorbereitung eines Komitee-Pakets anhand eines Datenraums, Überwachung von Signalen über Zielunternehmen. Schlecht gerahmte Fälle (Treffen einer Investitionsentscheidung, Senden einer Mitteilung an einen LP ohne Korrekturlesen) sind keine Fälle für Agenten, sondern Fälle für assistierte Menschen.
Ein guter Agent hat vier Eigenschaften: einen klaren Umfang, menschliche Aufsicht bei jedem sensiblen Schritt, vollständige Nachvollziehbarkeit und Umkehrbarkeit im Falle eines unerwarteten Verhaltens. Bodic entwickelt seine Agenten im Rahmen seiner maßgeschneiderten Entwicklungen nach diesen Grundsätzen.