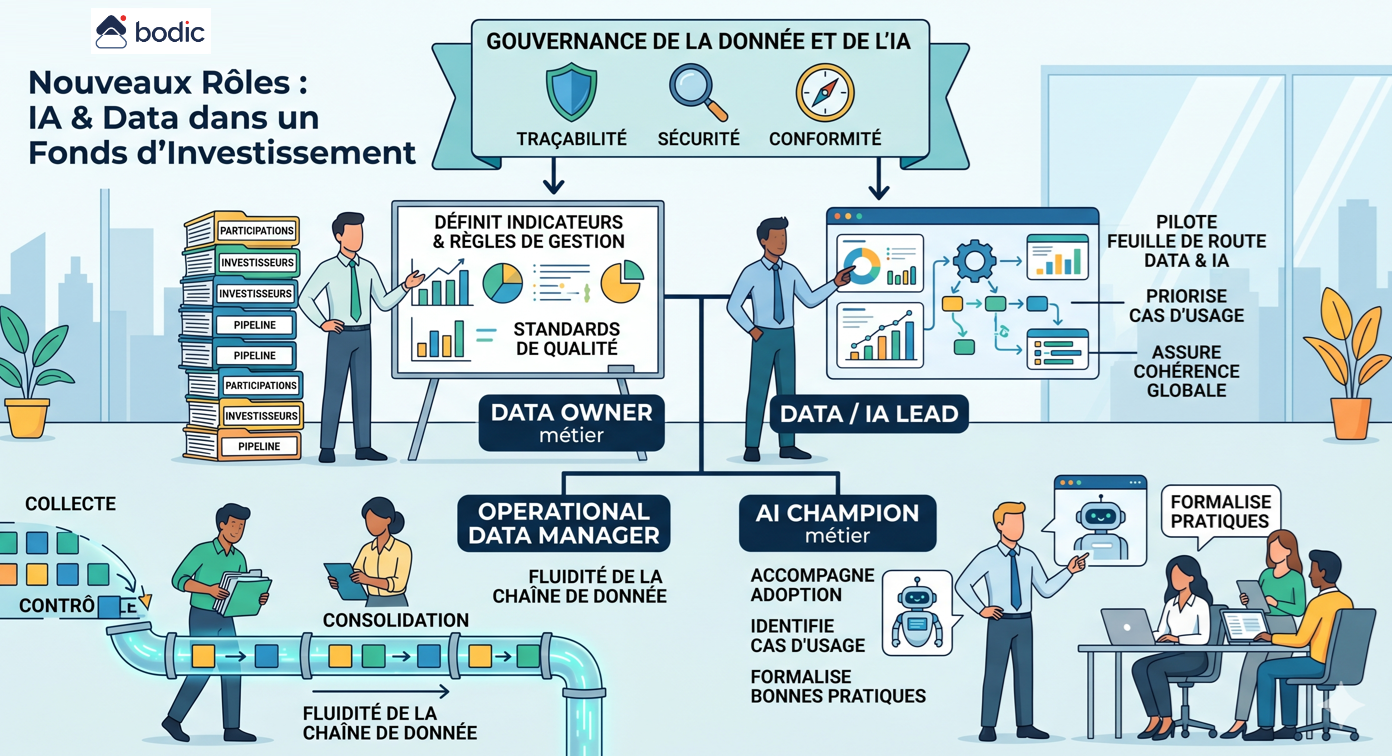
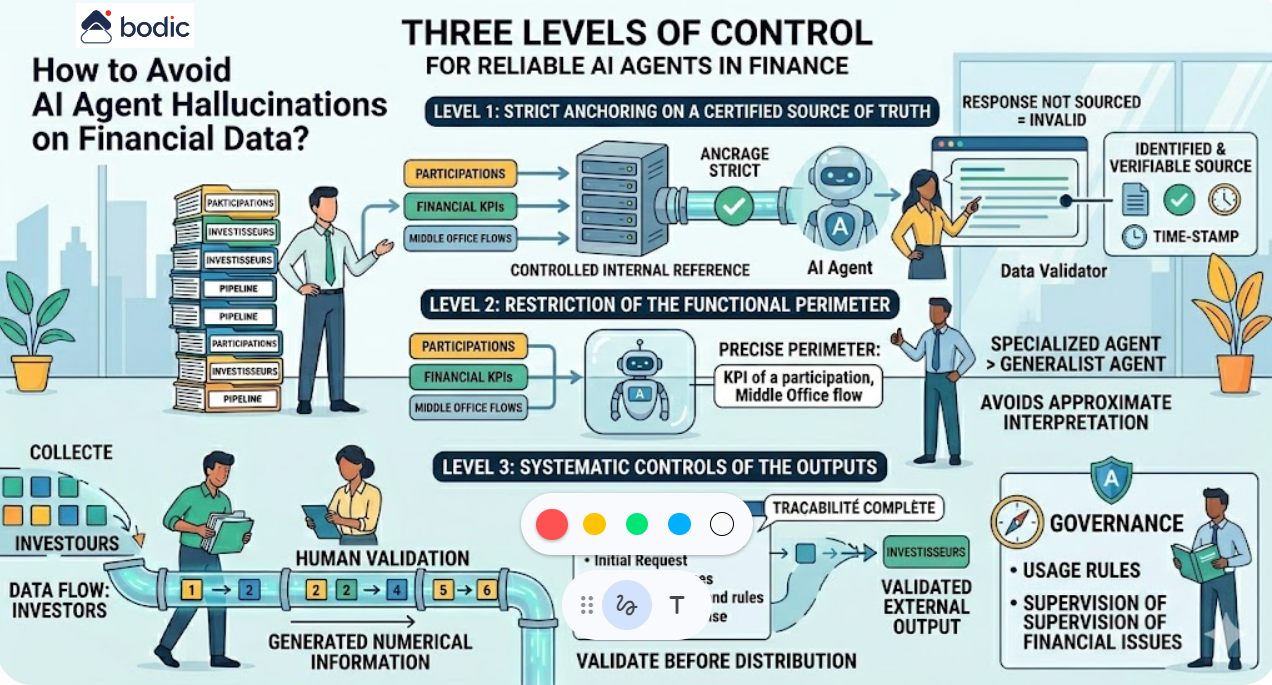
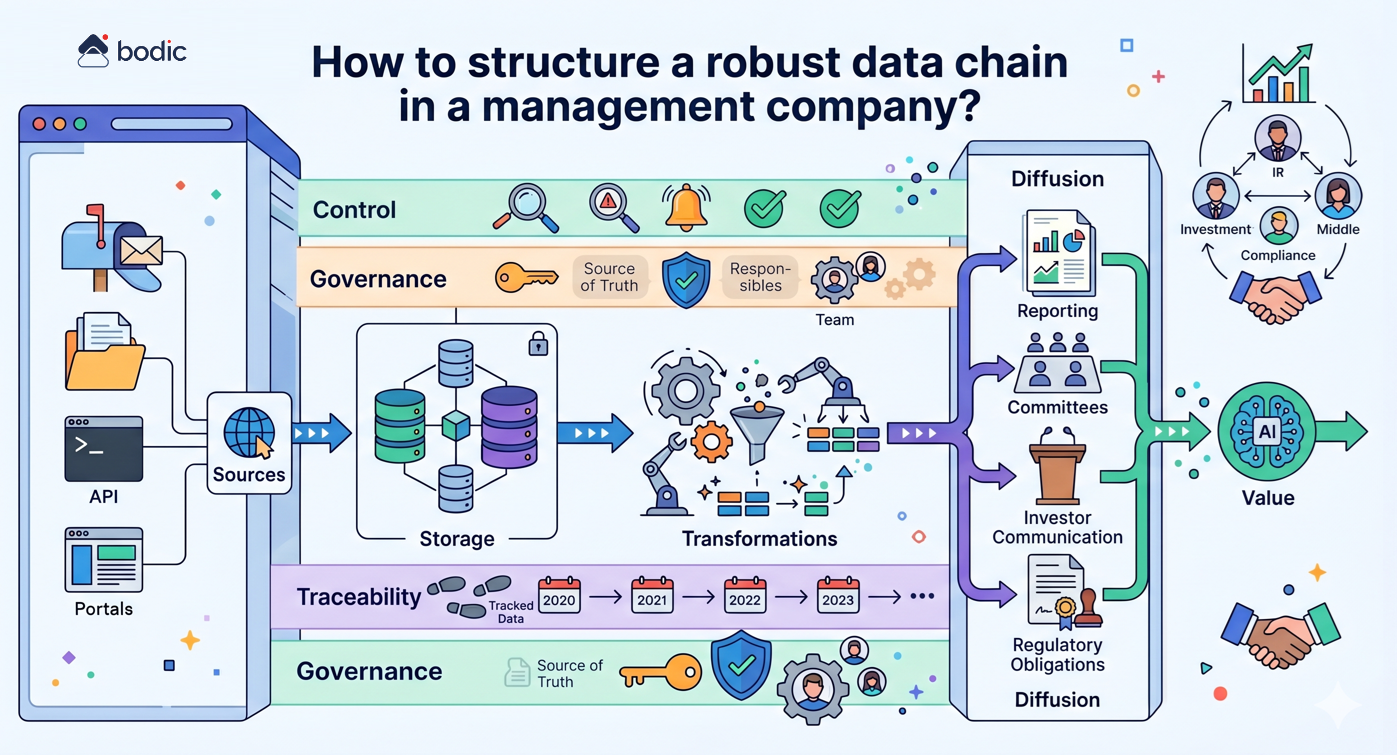
Da dove si parte con l'IA in un fondo?
La questione di dove iniziare con l'IA in un fondo è spesso affrontata dal punto di vista sbagliato. Il problema non è scegliere uno strumento, ma individuare dove l'IA può concretamente migliorare l'efficienza operativa, la qualità dei dati o la qualità del processo decisionale.
Nella maggior parte delle società di gestione patrimoniale, i primi vantaggi non si riscontrano in applicazioni complesse o "spettacolari". Si tratta invece di attività ripetitive e dispendiose in termini di tempo, con scarso valore aggiunto intellettuale: consolidamento di rapporti, preparazione di sintesi, ricerca di informazioni nei documenti, produzione di report, strutturazione di dati provenienti da file eterogenei o elaborazione di e-mail ricorrenti.
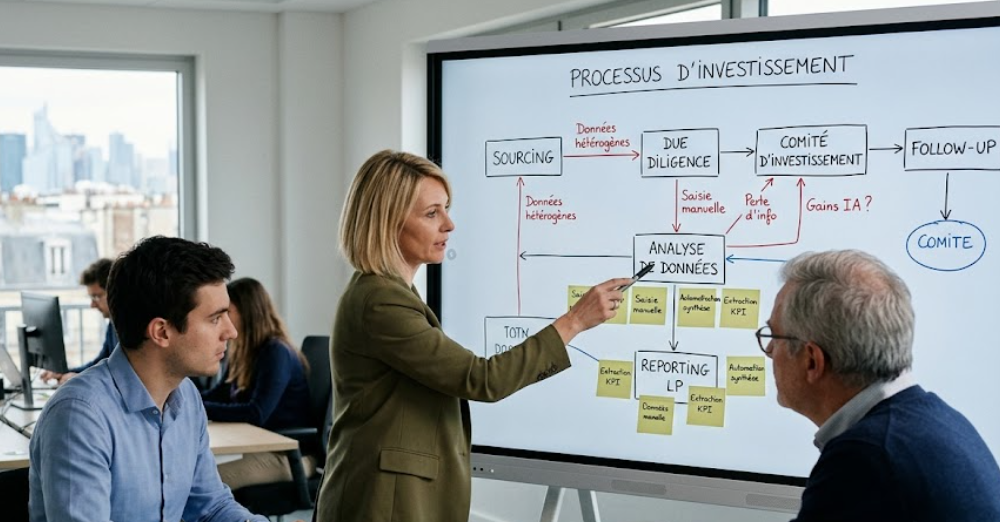
Il primo passo è quindi l'analisi dei processi esistenti. Dobbiamo capire come lavorano effettivamente i team: dove fluiscono i dati, quali strumenti vengono utilizzati, dove ci sono doppi inserimenti, rielaborazioni manuali, perdita di informazioni o dipendenze da Excel.
Questa fase di mappatura è essenziale, in quanto ci permette di identificare le aree di attrito operativo e i punti in cui l'IA può apportare benefici immediati senza modificare radicalmente l'organizzazione.
La seconda fase prevede la strutturazione della catena dei dati al minimo. Anche l'IA ad alte prestazioni produce scarsi risultati se si basa su dati incoerenti, dispersi o non governati. Non è necessario costruire subito un'architettura complessa, ma occorre una base affidabile: dati centralizzati, definizioni comuni e regole minime di convalida.
Una volta gettate queste basi, è possibile lanciare alcuni casi d'uso mirati, con tre caratteristiche: portata limitata, valore misurabile e basso rischio operativo.
I progetti più efficaci sono spesso molto pragmatici: automatizzare i riepiloghi dei promemoria, estrarre informazioni da una data room, preparare report LP, assistere nella ricerca di documenti o strutturare KPI partecipativi.
L'errore classico è quello di voler implementare una strategia globale di IA prima di aver stabilizzato i dati e i fondamenti operativi. Al contrario, i fondi che compiono i progressi più efficaci sono quelli che costruiscono gradualmente: strutturazione dei dati, primi casi d'uso aziendali, costruzione delle competenze dei team, quindi industrializzazione.
L'IA deve essere vista come uno strato di accelerazione in cima a un'organizzazione che ha già imparato l'arte. Senza basi solide, amplifica le debolezze esistenti. Con una catena di dati strutturata e usi ben definiti, diventa una leva operativa estremamente potente.
Nella maggior parte delle società di gestione patrimoniale, i primi vantaggi non si riscontrano in applicazioni complesse o "spettacolari". Si tratta invece di attività ripetitive e dispendiose in termini di tempo, con scarso valore aggiunto intellettuale: consolidamento di rapporti, preparazione di sintesi, ricerca di informazioni nei documenti, produzione di report, strutturazione di dati provenienti da file eterogenei o elaborazione di e-mail ricorrenti.
Il primo passo è quindi l'analisi dei processi esistenti. Dobbiamo capire come lavorano effettivamente i team: dove fluiscono i dati, quali strumenti vengono utilizzati, dove ci sono doppi inserimenti, rielaborazioni manuali, perdita di informazioni o dipendenze da Excel.
Questa fase di mappatura è essenziale, in quanto ci permette di identificare le aree di attrito operativo e i punti in cui l'IA può apportare benefici immediati senza modificare radicalmente l'organizzazione.
La seconda fase prevede la strutturazione della catena dei dati al minimo. Anche l'IA ad alte prestazioni produce scarsi risultati se si basa su dati incoerenti, dispersi o non governati. Non è necessario costruire subito un'architettura complessa, ma occorre una base affidabile: dati centralizzati, definizioni comuni e regole minime di convalida.
Una volta gettate queste basi, è possibile lanciare alcuni casi d'uso mirati, con tre caratteristiche: portata limitata, valore misurabile e basso rischio operativo.
I progetti più efficaci sono spesso molto pragmatici: automatizzare i riepiloghi dei promemoria, estrarre informazioni da una data room, preparare report LP, assistere nella ricerca di documenti o strutturare KPI partecipativi.
L'errore classico è quello di voler implementare una strategia globale di IA prima di aver stabilizzato i dati e i fondamenti operativi. Al contrario, i fondi che compiono i progressi più efficaci sono quelli che costruiscono gradualmente: strutturazione dei dati, primi casi d'uso aziendali, costruzione delle competenze dei team, quindi industrializzazione.
L'IA deve essere vista come uno strato di accelerazione in cima a un'organizzazione che ha già imparato l'arte. Senza basi solide, amplifica le debolezze esistenti. Con una catena di dati strutturata e usi ben definiti, diventa una leva operativa estremamente potente.