¿Por dónde se empieza realmente con la IA en un fondo?
La cuestión de por dónde empezar con la IA en un fondo se aborda a menudo desde el ángulo equivocado. No se trata de elegir una herramienta, sino de identificar dónde la IA puede mejorar concretamente la eficiencia operativa, la calidad de los datos o la calidad de la toma de decisiones.
En la mayoría de las empresas de gestión de activos, las primeras ganancias no se encuentran en aplicaciones complejas o "espectaculares". Por el contrario, aparecen en tareas repetitivas, que consumen mucho tiempo y tienen poco valor añadido intelectual: consolidar informes, preparar resúmenes, buscar información en documentos, elaborar informes, estructurar datos de archivos heterogéneos o procesar correos electrónicos recurrentes.
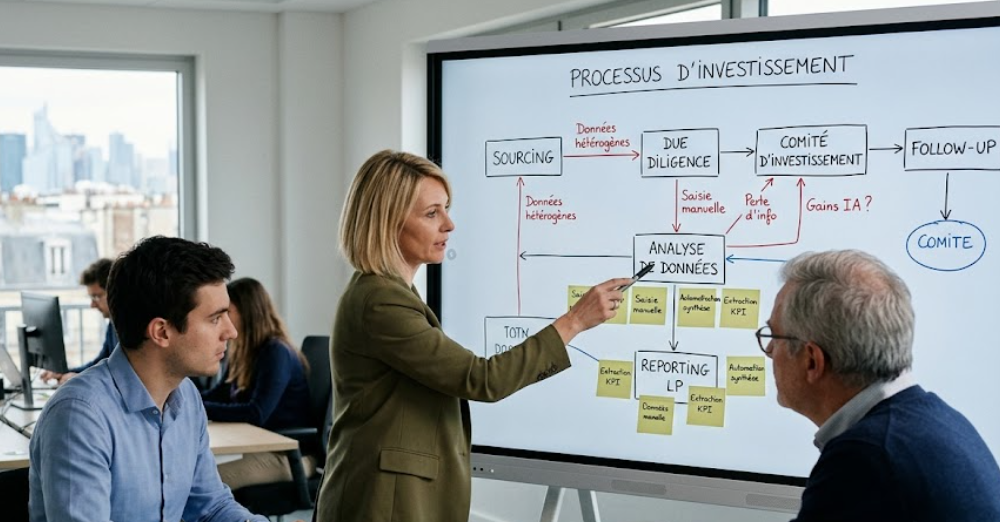
Así que el primer paso es analizar los procesos existentes. Tenemos que entender cómo trabajan realmente los equipos: por dónde fluyen los datos, qué herramientas se utilizan, dónde hay doble entrada, reprocesamiento manual, pérdida de información o dependencias de Excel.
Esta fase de mapeo es esencial, ya que nos permite identificar las áreas de fricción operativa y los puntos en los que la IA puede aportar beneficios inmediatos sin cambiar radicalmente las organizaciones.
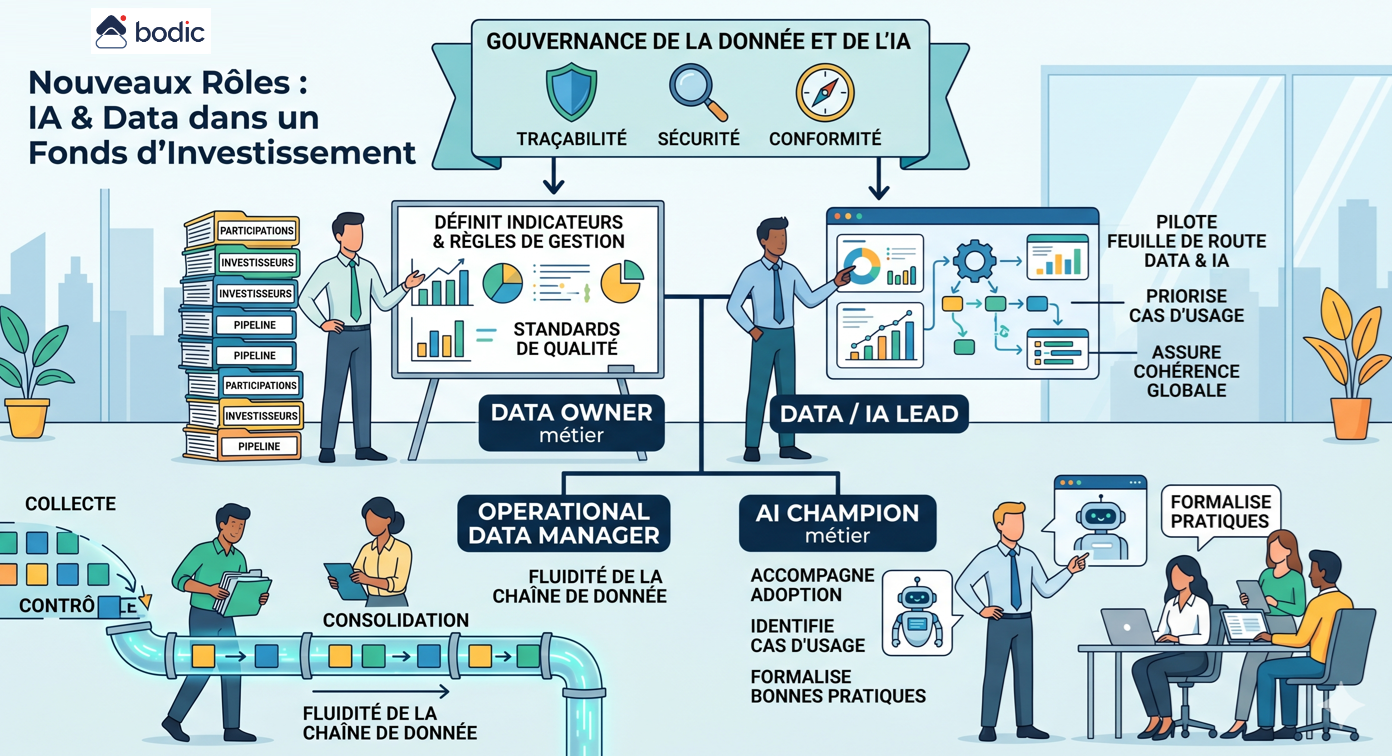
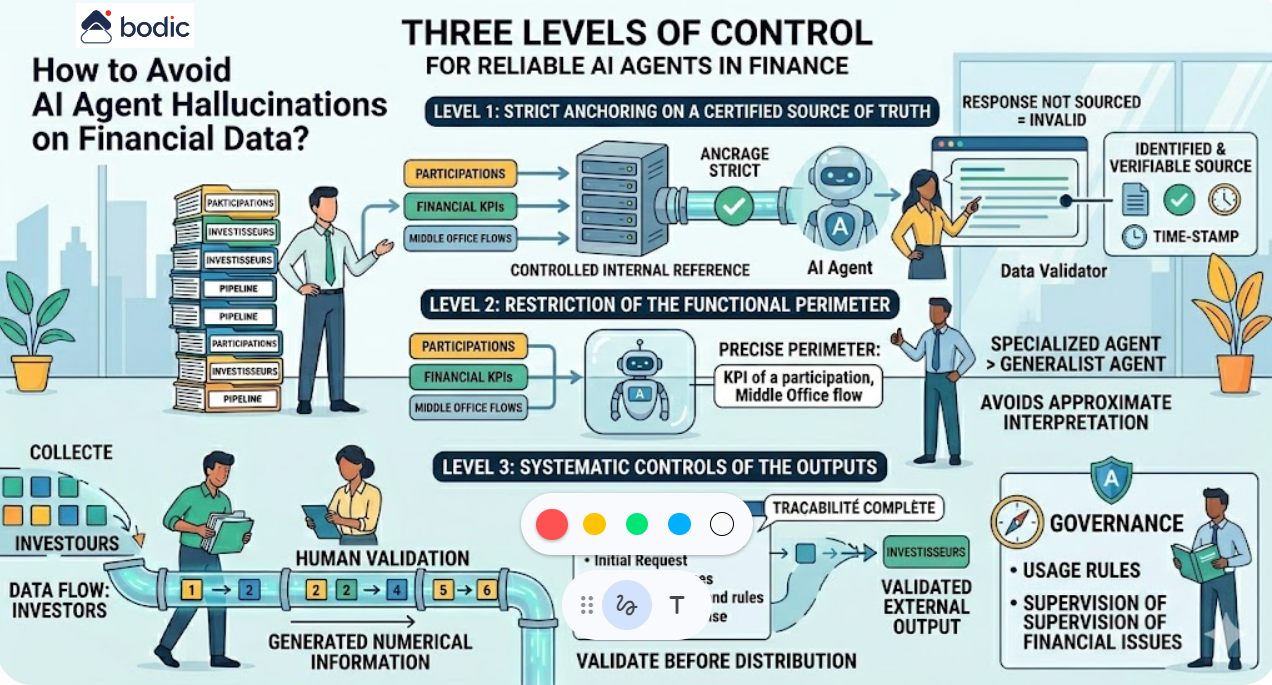
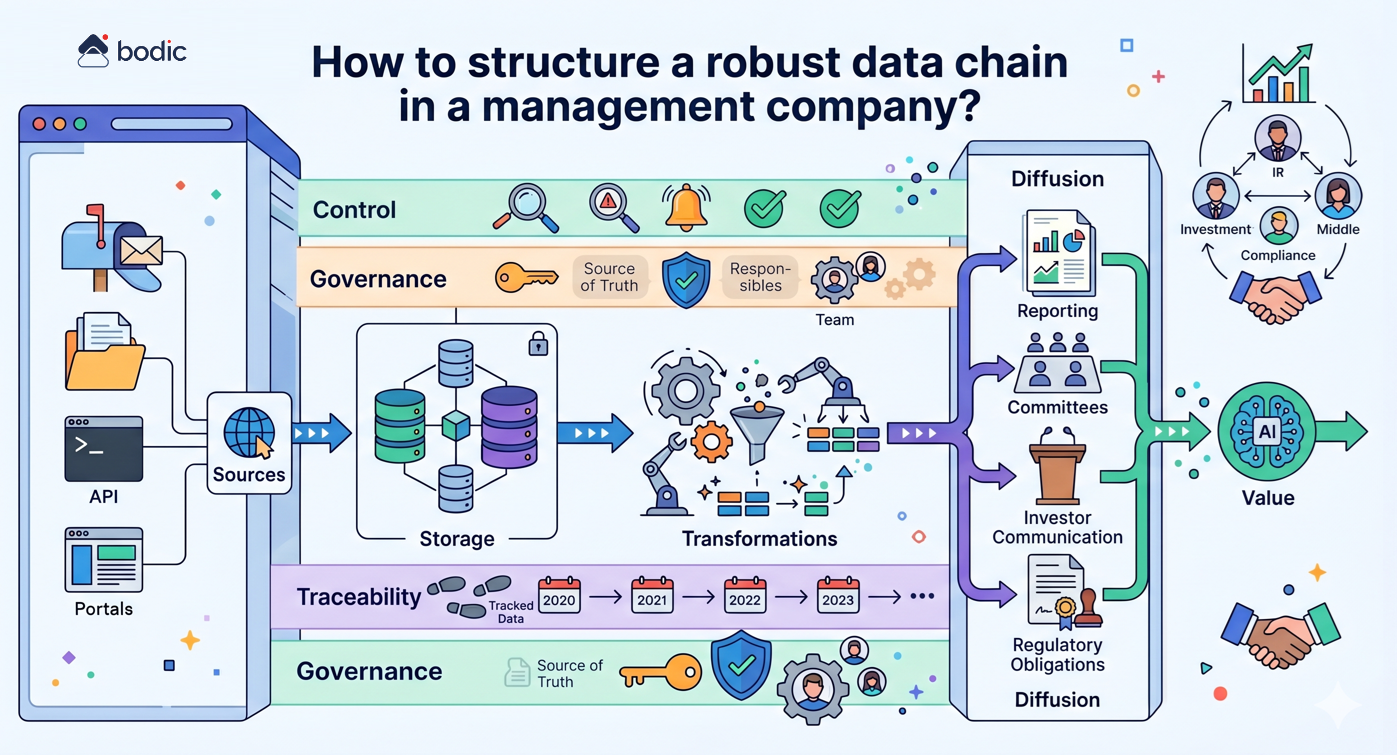
La segunda fase consiste en estructurar la cadena de datos al mínimo. Incluso la IA de alto rendimiento produce resultados pobres si se basa en datos incoherentes, dispersos o no controlados. No es necesario construir una arquitectura compleja de inmediato, pero sí unos cimientos fiables: datos centralizados, definiciones comunes y reglas de validación mínimas.
Una vez sentadas estas bases, es posible lanzar unos pocos casos de uso específicos, con tres características: un alcance limitado, un valor mensurable y un riesgo operativo bajo.
Los proyectos más eficaces suelen ser muy pragmáticos: automatizar resúmenes de notas, extraer información de una sala de datos, preparar informes de LP, ayudar en la búsqueda de documentos o estructurar KPI participativos.
El error clásico es querer desplegar una estrategia global de IA antes de haber estabilizado los datos y los fundamentos operativos. Por el contrario, los fondos que progresan de forma más eficaz son los que construyen gradualmente: estructuración de los datos, primeros casos de uso empresarial, desarrollo de las competencias de los equipos y, a continuación, industrialización.
La IA debe verse como una capa de aceleración sobre una organización que ya domina el arte. Sin unos cimientos sólidos, amplifica las debilidades existentes. Con una cadena de datos estructurada y usos bien definidos, se convierte en una palanca operativa extremadamente potente.
En la mayoría de las empresas de gestión de activos, las primeras ganancias no se encuentran en aplicaciones complejas o "espectaculares". Por el contrario, aparecen en tareas repetitivas, que consumen mucho tiempo y tienen poco valor añadido intelectual: consolidar informes, preparar resúmenes, buscar información en documentos, elaborar informes, estructurar datos de archivos heterogéneos o procesar correos electrónicos recurrentes.
Así que el primer paso es analizar los procesos existentes. Tenemos que entender cómo trabajan realmente los equipos: por dónde fluyen los datos, qué herramientas se utilizan, dónde hay doble entrada, reprocesamiento manual, pérdida de información o dependencias de Excel.
Esta fase de mapeo es esencial, ya que nos permite identificar las áreas de fricción operativa y los puntos en los que la IA puede aportar beneficios inmediatos sin cambiar radicalmente las organizaciones.
La segunda fase consiste en estructurar la cadena de datos al mínimo. Incluso la IA de alto rendimiento produce resultados pobres si se basa en datos incoherentes, dispersos o no controlados. No es necesario construir una arquitectura compleja de inmediato, pero sí unos cimientos fiables: datos centralizados, definiciones comunes y reglas de validación mínimas.
Una vez sentadas estas bases, es posible lanzar unos pocos casos de uso específicos, con tres características: un alcance limitado, un valor mensurable y un riesgo operativo bajo.
Los proyectos más eficaces suelen ser muy pragmáticos: automatizar resúmenes de notas, extraer información de una sala de datos, preparar informes de LP, ayudar en la búsqueda de documentos o estructurar KPI participativos.
El error clásico es querer desplegar una estrategia global de IA antes de haber estabilizado los datos y los fundamentos operativos. Por el contrario, los fondos que progresan de forma más eficaz son los que construyen gradualmente: estructuración de los datos, primeros casos de uso empresarial, desarrollo de las competencias de los equipos y, a continuación, industrialización.
La IA debe verse como una capa de aceleración sobre una organización que ya domina el arte. Sin unos cimientos sólidos, amplifica las debilidades existentes. Con una cadena de datos estructurada y usos bien definidos, se convierte en una palanca operativa extremadamente potente.